Stable Diffusion로 txt2img 파인튜닝해보기(3)

∣
2023년 9월 23일
본 글은 keras 공식 홈페이지의 스테이블 디퓨전 파인튜닝 예시 코드를 기반으로 작성됐습니다.
함께 학습한 안효주님의 블로그 바로가기
이제 학습이 완료된 모델을 기반으로 서버를 열어 api 통신으로 ui를 통해 캐릭터 이미지를 생성할 계획이다
웹 서버를 열기위해 파이썬의 flask를 사용할 것이다.
from flask import Flask, render_template, request, jsonify, send_file
import keras_cv
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import cv2
import io
훈련 후 모델 명을 바꾸었습니다.
먼저 app 객체를 만들고 모델을 불러와 미리 준비시켰습니다.
pokemon_model은 기존 코드 변수명을 그대로 가져왔습니다. 변경 가능합니다.
app = Flask(__name__)
# 미리 학습된 모델 로드
weights_path = "./frist_diffusion.h5"
img_height = img_width = 512
pokemon_model = keras_cv.models.StableDiffusion(
img_width=img_width, img_height=img_height
)
pokemon_model.diffusion_model.load_weights(weights_path)
generate 컨트롤러를 get 타입으로 생성하였습니다. 매개변수로 prompt를 받아 하나의 이미지를 생성 후 이를 바이트배열로 반환하였습니다.
@app.route("/generate", methods=["GET"])
def index():
if request.method == "GET":
# POST 요청에서 프롬프트 데이터 가져오기
prompt = request.form["prompt"]
images_to_generate = 1
# 텍스트를 이미지로 변환
generated_images = pokemon_model.text_to_image(
prompt, batch_size=images_to_generate, unconditional_guidance_scale=40
)
# 이미지를 바이트 스트림으로 변환
image_byte_array = io.BytesIO()
# 이미지 크기 설정
image_height, image_width = generated_images[0].shape[
:2
] # 첫 번째 이미지의 크기를 기준으로 설정
image_byte_array = io.BytesIO()
# 이미지 크기를 800x600으로 고정하고 저장
fixed_size_image = cv2.resize(generated_images[0], (800, 600))
plt.imsave(image_byte_array, fixed_size_image.astype(np.uint8), format="png")
image_byte_array.seek(0)
image_byte_array.seek(0)
# 이미지를 브라우저에게 반환
return send_file(image_byte_array, mimetype="image/png")
서버를 5556포트에서 열어 실행했습니다.
if __name__ == "__main__":
app.run(port=5556)
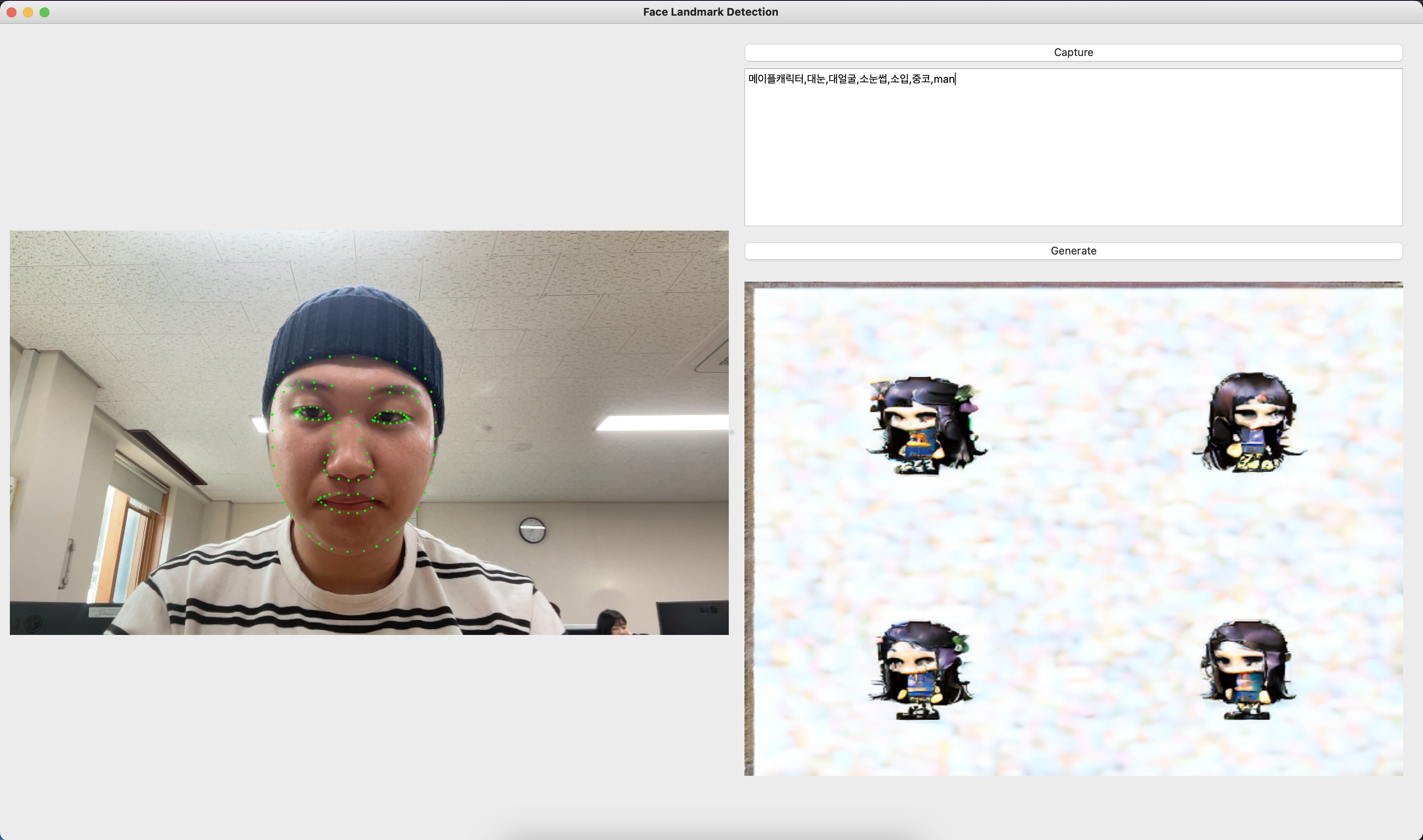
전에 만든 Qt5 ui를 실행하고 서버와 통신하여 이미지 캐릭터를 생성해 보았습니다.
텍스트로 뽑아볼 수 있는 특성이 너무 한정적이라 얼굴을 크게 잘 반영하지 않는 듯 하다.
70장 정도의 적은 데이터 셋이기 때문에 넓은 차원, 파라미터를 가지고 예측하기란 힘들어 보였다.
그래서 텍스트로 했지만 확실히 이상하다. 로라를 공부해서 img2img를 해보아야겠다.
댓글