Transformer 구현

∣
2023년 8월 5일
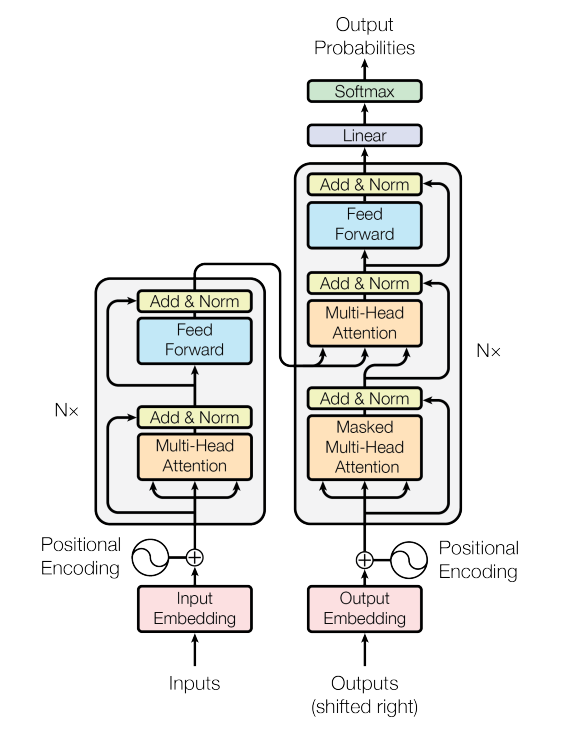
class Tokenizer:
def __init__(self, token_dict):
self.token_dict = token_dict
self.token_to_id = {token: i for i, token in enumerate(token_dict['char'])}
self.vocab_size = len(self.token_dict)
self.max_length = 128
def tokenize(self, sentence):
tokens = [self.token_to_id.get(char, self.token_to_id['<blank>']) for char in sentence]
if len(tokens) > self.max_length:
tokens = tokens[:self.max_length]
else:
pad_size = self.max_length - len(tokens)
tokens += [self.token_to_id['<pad>']] * pad_size
return torch.tensor(tokens, dtype=torch.float32)
class PositionalEncoding:
def __init__(self, max_len, d_model):
self.max_len = max_len
self.d_model = d_model
def __call__(self, length):
pe = torch.zeros(length, self.d_model)
position = torch.arange(0, length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, self.d_model, 2).float() * -(math.log(10000.0) / self.d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.head_dim = d_model // num_heads
self.query_fc = nn.Linear(d_model, d_model)
self.key_fc = nn.Linear(d_model, d_model)
self.value_fc = nn.Linear(d_model, d_model)
self.out_fc = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# Linear transformations to get query, key, and value for each head
query = self.query_fc(query)
key = self.key_fc(key)
value = self.value_fc(value)
# Reshape query, key, and value for multi-head attention
query = query.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) # (batch_size, num_heads, seq_len, head_dim)
key = key.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) # (batch_size, num_heads, seq_len, head_dim)
value = value.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2) # (batch_size, num_heads, seq_len, head_dim)
# Attention scores and scaled dot-product attention
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_dim) # (batch_size, num_heads, seq_len, seq_len)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(attention_weights, value) # (batch_size, num_heads, seq_len, head_dim)
# Concatenate and reshape multi-head attention outputs
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # (batch_size, seq_len, d_model)
# Linear transformation to get the final output
output = self.out_fc(attention_output)
return output
class AddAndNorm(nn.Module):
def __init__(self, d_model, dropout=0.1):
super(AddAndNorm, self).__init__()
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(d_model)
def forward(self, x, residual):
x = x + self.dropout(residual)
x = self.norm(x)
return x
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.activation = nn.ReLU()
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.dropout(x)
x = self.linear2(x)
return x
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(TransformerEncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
self.add_and_norm1 = AddAndNorm(d_model, dropout)
self.add_and_norm2 = AddAndNorm(d_model, dropout)
def forward(self, x, mask=None):
# Multi-Head Self-Attention
attention_output = self.self_attention(x, x, x, mask=mask)
# Add and Norm for the first time
x = self.add_and_norm1(attention_output, x)
# Feed-Forward
feed_forward_output = self.feed_forward(x)
# Add and Norm for the second time
x = self.add_and_norm2(feed_forward_output, x)
return x
class TransformerEncoder(nn.Module):
def __init__(self, d_model, num_heads, d_ff, num_layers, dropout=0.1):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([TransformerEncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, mask=None):
for layer in self.layers:
x = layer(x, mask=mask)
return x
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(TransformerDecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.encoder_attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff, dropout)
self.add_and_norm1 = AddAndNorm(d_model, dropout)
self.add_and_norm2 = AddAndNorm(d_model, dropout)
self.add_and_norm3 = AddAndNorm(d_model, dropout)
def forward(self, x, encoder_output, self_mask=None, encoder_mask=None):
# Multi-Head Self-Attention
self_attention_output = self.self_attention(x, x, x, mask=self_mask)
# Add and Norm for the first time
x = self.add_and_norm1(self_attention_output, x)
# Multi-Head Encoder-Decoder Attention
encoder_attention_output = self.encoder_attention(x, encoder_output, encoder_output, mask=encoder_mask)
# Add and Norm for the second time
x = self.add_and_norm2(encoder_attention_output, x)
# Feed-Forward
feed_forward_output = self.feed_forward(x)
# Add and Norm for the third time
x = self.add_and_norm3(feed_forward_output, x)
return x
class TransformerDecoder(nn.Module):
def __init__(self, d_model, num_heads, d_ff, num_layers, dropout=0.1):
super(TransformerDecoder, self).__init__()
self.layers = nn.ModuleList([TransformerDecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, encoder_output, self_mask=None, encoder_mask=None):
for layer in self.layers:
x = layer(x, encoder_output, self_mask=self_mask, encoder_mask=encoder_mask)
return x
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
tokens, label = self.data[idx]
# 레이블을 1 또는 0으로 변환하고 dtype을 torch.float32로 설정합니다.
label = torch.tensor([1.0 if label == "진실" else 0.0], dtype=torch.float32)
return tokens, label
# 이진 분류 모델
class BinaryClassificationModel(nn.Module):
def __init__(self, d_model, num_heads, d_ff, num_layers, dropout=0.1):
super(BinaryClassificationModel, self).__init__()
self.encoder = TransformerEncoder(d_model, num_heads, d_ff, num_layers, dropout)
self.classifier = nn.Linear(d_model, 1)
self.max_length = 512
def forward(self, x, mask=None):
x = self.encoder(x, mask)
x = self.classifier(x)
return x
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader, Dataset
data = [
("우리는 daiv에서 자연어 처리를 배우고 있어요.", "진실"),
("우리는 daiv에서 영상 처리를 배우고 있어요.", "거짓"),
("우리는 daiv에서 자연어 처리에 관심이 있다.", "진실"),
("우리는 daiv에서 자연어 활용을 배우고 있어요.", "진실"),
("우리는 영상 처리를 배우고 있어요.", "거짓"),
("우리는 자연어 처리에 관심이 있다.", "진실"),
]
# 토큰화
tokenizer = Tokenizer(token_dict)
tokenized_data = [(tokenizer.tokenize(sentence), label) for sentence, label in data]
# DataLoader 구성
batch_size = 1 # 배치 사이즈를 1로 설정하여 하나씩 처리하도록 설정
dataset = CustomDataset(tokenized_data)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 모델 초기화
model = BinaryClassificationModel(d_model, num_heads, d_ff, num_layers, dropout)
# 손실 함수와 옵티마이저
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 학습
num_epochs = 10
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
outputs = outputs.squeeze(dim=2)
outputs = outputs.squeeze()
labels = labels.float().squeeze()
loss = criterion(outputs.squeeze(), labels.float()) # 이진 분류이므로 레이블을 0 또는 1로 변환합니다.
loss.backward()
optimizer.step()
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")
# 테스트 문장 준비
test_sentence = "우리는 자연어 처리에 관심이 았다"
# 문장 토큰화
tokenized_test_sentence = tokenizer.tokenize(test_sentence)
# 모델 테스트
model.eval() # 모델을 평가 모드로 전환
with torch.no_grad():
output = model(tokenized_test_sentence.unsqueeze(0))
prediction = torch.sigmoid(output.squeeze()).item() # 이진 분류 문제이므로 시그모이드 함수를 적용하여 확률 값으로 변환합니다.
# 결과 출력
if prediction >= 0.5:
print("진실입니다.")
else:
print("거짓입니다.")

class Tokenizer:
def __init__(self, token_dict):
self.token_dict = token_dict
self.token_to_id = {token: i for i, token in enumerate(token_dict['char'])}
self.vocab_size = len(self.token_dict['char']) # Use the correct vocabulary size
self.max_length = 128
def tokenize(self, sentence):
tokens = [self.token_to_id.get(char, self.token_to_id['<blank>']) for char in sentence]
# sos 토큰 추가
tokens = [self.token_to_id['<sos>']] + tokens
# eos 토큰 추가
tokens.append(self.token_to_id['<eos>'])
if len(tokens) > self.max_length:
tokens = tokens[:self.max_length]
else:
pad_size = self.max_length - len(tokens)
tokens += [self.token_to_id['<pad>']] * pad_size
return torch.tensor(tokens, dtype=torch.float32)
def decode(self, tensor):
try:
tokens = [self.token_dict['char'][int(token)] for token in tensor if int(token) < len(self.token_dict['char']) and self.token_dict['char'][int(token)] != '']
except IndexError as e:
print("Error while decoding:", e)
print("Problematic token IDs:", [int(token) for token in tensor if int(token) >= len(self.token_dict['char'])])
tokens = []
text = ''.join(tokens)
return text
class Model(nn.Module):
def __init__(self, d_model, num_heads, d_ff, num_layers, dropout=0.1):
super(Model, self).__init__()
self.encoder = TransformerEncoder(d_model, num_heads, d_ff, num_layers, dropout)
self.classifier = nn.Linear(d_model, 1)
def forward(self, x, mask=None):
x = self.encoder(x, mask)
x = self.classifier(x)
return x
def generate_text(self, start_text, max_length=100):
with torch.no_grad():
input_tensor = tokenizer.tokenize(start_text)
input_tensor = input_tensor.unsqueeze(0) # 배치 차원 추가
current_length = input_tensor.size(1)
eos_token_id = tokenizer.token_to_id['<eos>']
while current_length < max_length:
outputs = self.encoder(input_tensor) # 디코더의 출력 크기를 d_model로 맞춤
next_token_id = torch.argmax(outputs[:, -1, :]) # 다음 토큰 예측
if next_token_id == eos_token_id:
break
eos_positions = (input_tensor == eos_token_id).nonzero(as_tuple=True)[1].tolist()
for pos in eos_positions:
input_tensor[0, pos] = next_token_id
# 기존 eos_positions 자리에서 한 칸 뒤에 eos 토큰을 둔다
eos_pos = pos + 1
input_tensor = torch.cat([input_tensor[:, :eos_pos], torch.tensor([[eos_token_id]], dtype=torch.float32, device=input_tensor.device), input_tensor[:, eos_pos:]], dim=1)
current_length += 1
# Remove the last token from the generated text
input_tensor = input_tensor[:, :-1]
eos_positions = (input_tensor == eos_token_id).nonzero(as_tuple=True)[1].tolist()
input_tensor = input_tensor[:, 1 : eos_positions[0]]
generated_text = tokenizer.decode(input_tensor.squeeze(0))
return generated_text
import torch
import torch.nn as nn
import torch.optim as optim
# 더미 데이터와 라벨 생성
data = [
"우리는 daiv에서 자연어 처리를 배우고 있어요.",
"우리는 daiv에서 영상 처리를 배우고 있어요.",
"우리는 daiv에서 자연어 처리에 관심이 있다.",
"우리는 daiv에서 자연어 활용을 배우고 있어요.",
"우리는 영상 처리를 배우고 있어요.",
"우리는 자연어 처리에 관심이 있다."
]
labels = [1, 0, 1, 1, 0, 1]
# 토크나이저 초기화
token_dict = {'char': ['<blank>', '<pad>', '<sos>', '<eos>'] + list(set(' '.join(data)))}
tokenizer = Tokenizer(token_dict)
# 더미 데이터 토크나이징 및 패딩
tokenized_data = [tokenizer.tokenize(sentence) for sentence in data]
labels_tensor = torch.tensor(labels, dtype=torch.float32)
# 데이터 로더 생성
batch_size = 1
data = torch.utils.data.TensorDataset(torch.stack(tokenized_data), labels_tensor)
dataloader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True)
# 모델 초기화
d_model = 128
num_heads = 4
d_ff = 512
num_layers = 2
model = Model(d_model, num_heads, d_ff, num_layers)
# 손실 함수와 옵티마이저
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 학습
num_epochs = 10
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
outputs = outputs.squeeze(dim=2)
labels = labels.unsqueeze(1) # 라벨 텐서의 형태를 [batch_size, 1]로 변경
loss = criterion(outputs, labels) # 이진 분류이므로 레이블은 0 또는 1로 주어짐
loss.backward()
optimizer.step()
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")
# 테스트 문장 준비
start_text = "우리는 daiv에"
generated_text = model.generate_text(start_text, max_length=200)
print("Generated Text:", generated_text)

댓글