autotrain-advanced을 활용한 Llama2 모델 학습

∣
2023년 9월 9일

라마2는 오픈AI에서 개발한 대규모 언어 모델(LLM)이다. 2023년 6월 30일에 공개되었으며, 1370억 개의 파라미터를 가지고 있다. 라마2는 텍스트 생성, 언어 번역, 질문에 대한 답변과 같은 다양한 작업에서 GPT-3와 유사한 성능을 보여준다.
라마2의 가장 큰 특징은 오픈소스라는 점이다. 이는 누구나 라마2를 자유롭게 사용할 수 있다는 것을 의미한다. 또한, 라마2는 GPT-3와 달리 상업용으로도 사용할 수 있다.
 아래를 클릭하면 autotrain-advanced 깃허브를 접속할 수 있다.
아래를 클릭하면 autotrain-advanced 깃허브를 접속할 수 있다.
아래 명령어를 통해 설치할 수 있다.
pip install -q autotrain-advanced
허깅페이스에 접속해서 새로운 데이터 셋을 만든다.
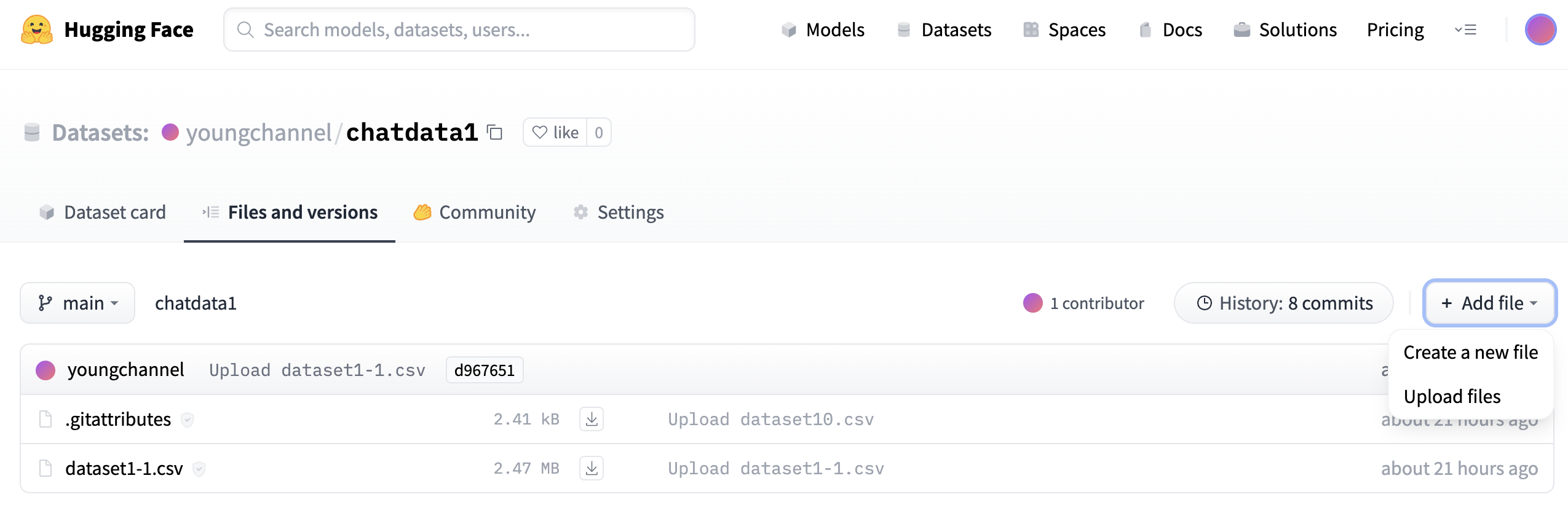
준비한 데이터 파일을 업로드 하면 데이터 셋이 등록이 된다.
터미널을 열고 아래의 명령어를 입력하면 학습이 시작된다. [내용] 부분을 자신의 내용으로 입력하면 된다.
autotrain llm --train \
--project_name "[생성할 프로젝트 이름]" \
--model "[허깅페이스의 사용할 모델이름]" \
--data_path "[데이터셋 주소]" \
--text_column "text" \
--use_peft \
--use_int4 \
--learning_rate 2e-4 \
--train_batch_size 8 \
--num_train_epochs 3 \
--trainer sft \
아래는 예시이다.
autotrain llm --train \
--project_name "myLama2" \
--model "quantumaikr/KoreanLM-llama-2-7B-finetuned" \
--data_path "myaccount/data" \
--text_column "text" \
--use_peft \
--use_int4 \
--learning_rate 2e-4 \
--train_batch_size 8 \
--num_train_epochs 3 \
--trainer sft \
학습이 된다!. 굉장히 오래 걸린다.
댓글