0장 들어가며 [이것이 데이터 분석이다]

∣
2023년 11월 15일
교재 이미지나 화면 등등을 최대한 공개 안한 상태로 글을 작성하겠지만 문제가 되지 않겠죠?… 문제가 있다면 이메일로 연락주세요!…
먼저 교재에서는 아나콘다를 설치하라고 한다. 난 이미 설치가 돼 있기 때문에 패스한다.
혹여나 내 글을 보고 공부를 하시는 왕초보 분이 있다면 꼭 터미널을 열었을 때 제일 처음 (base)라고 나와야 설치가 된겁니다.
혹여나 컴퓨터 사양이 부족하시다면 미니콘다 설치하는것을 추천드립니다!
만약 리눅스 환경에서 시작한다면!(당신은 변태입니다.) 아래 링크를 참조해주세요
아래 명령어로 설치하고 서버를 실행시키면 된다. localhost url이 나오는데 그걸 웹 브라우저에 넣으면 주피터에 접속된다. 나는 근데 vscode 주피터에서 할거다 하하
//설치 명령어
pip install jupyter
//실행명령어
jupyter notebook
먼저 필요한 패키지들은 설치한다. pandas, numpy, matplotlib은 하나의 도구이다. 간단하게 아래 명령어로 설치 가능하다.
pip install pandas numpy matplotlib
먼저 성공정으로 설치가 됐다면 파이썬 파일에서 해당 패키지를 참조해야 컴파일러가 이를 인식하기 한다. 간단하게 아래 명령어로 참조가능하다.
여기서 as는 별명?이다 패키지를 사용할떄 “pandas.땡땡땡()”과 같은 형식으로 활용한다. pandas를 매번 치는 것보다 pd만 치는게 편하기 때문에 이렇게 별명을 설정하는 것이다
import pandas as pd
리스트 3개를 선언한다. zip파일을 하게되면 인덱스단위로 두개의 리스트를 하나씩 묶고 이를 리스트화 시켜 아래와 같은 결과값을 얻는다. 그후 데이터 프레임을 생성한다.
# 판다스의 데이터 프레임을 생성합니다.
names = ['Bob', 'Jessica', 'Mary', 'John', 'Mel']
births = [968, 155, 77, 578, 973]
custom = [1, 5, 25, 13, 23232]
BabyDataSet = list(zip(names, births))
# [('Bob', 968), ('Jessica', 155), ('Mary', 77), ('John', 578), ('Mel', 973)]
df = pd.DataFrame(data = BabyDataSet, columns= ['Names', 'Births'])
# 데이터 프레임의 상단 부분을 출력한다.
df.head()
데이터 프레임의 결과이다.
| Names | Births | |
|---|---|---|
| 0 | Bob | 968 |
| 1 | Jessica | 155 |
| 2 | Mary | 77 |
| 3 | John | 578 |
| 4 | Mel | 973 |
df.dtypes
# df.dtypes의 출력 값
Names object
Births int64
dtype: object
df.index
# df.index의 출력 값
RangeIndex(start=0, stop=5, step=1)
본 결과는 시리즈라는 객체를 출력한 것이다.
df.columns
# df.columns의 출력 값
Index(['Names', 'Births'], dtype='object')
본 결과는 데터 프레임을 출력한 것이다.
df[0:3]
| Names | Births | |
|---|---|---|
| 0 | Bob | 968 |
| 1 | Jessica | 155 |
| 2 | Mary | 77 |
df에서 Births 값이 100보다 큰 행들만 골라 출력하는 구문이다.
df[df['Births'] > 100]
| Names | Births | |
|---|---|---|
| 0 | Bob | 968 |
| 1 | Jessica | 155 |
| 3 | John | 578 |
| 4 | Mel | 973 |
df에서 Births 값의 평균을 구하기이다. 교재에서는 df.mean()으로 설명돼 있지만 파이써 버젼에 따라 텍스트 값이 있어 에러가 나기도 한다. 나는 다음과 같이 수행했다.
df['Births'].mean()
550.2
NumPy(넘파이)는 파이썬에서 사용되는 수치 연산을 위한 라이브러리로, 고성능 다차원 배열 및 행렬 객체와 이러한 배열을 다루기 위한 다양한 함수와 도구를 제공한다. 다음과 같이 참조하며 약어로 np를 자주 사용한다.
import numpy as np
다음과 같은 명령어로 넘파이 배열을 생성할 수 있다
arr = np.arange(15)
arr
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
만일 차원을 변형하고 싶다면 reshape 명령어를 사용가능하다. 다음은 1차원 배열 3개와 2차원 배열 5개로 값의 형태를 변형한 예제이다.
arr = np.arange(15).reshape(3, 5)
arr
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
shape 명령어로 배열의 구성 모양을 볼 수 있다.
arr.shape
(3, 5)
dtype 명령어를 통해 자료형을 확인할 수 있다.
arr.dtype
dtype('int64')
zeros함수로 전부 0으로 채워진 배열을 생성가능하다. 그외에도 모두 1로 채우는 ones 등이 있다.
arr = np.zeros((3,4))
arr
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
먼저 두 배열을 같은 모양과 자료형으로 생성한다.
arr1 = np.array([
[1,2,3],
[4,5,6]
], dtype= np.float64)
arr2 = np.array([
[7,8,9],
[10,11,12]
], dtype= np.float64)
더하기 예제이다. 배열의 인덱스 위치에 맞춰서 값들이 더해진 것을 확인할 수 있었다.
arr1 + arr2
array([[ 8., 10., 12.],
[14., 16., 18.]])
빼기 예제이다. 배열의 인덱스 위치에 맞춰서 값들이 빼진 것을 확인할 수 있었다.
arr1 - arr2
array([[-6., -6., -6.],
[-6., -6., -6.]])
나머지 곱하기 나누기도 동일하게 인덱스 위치에 따라 연산이 된다.
Matplotlib(맷플롯립)은 파이썬에서 데이터 시각화를 위한 가장 널리 사용되는 라이브러리 중 하나입니다. 다음과 같이 참조 가능합니다. 형태가 조금 다른 이유는 주로 그래프를 그리는 기능은 matplotlib 패키지에서 pyplot이라는 기능을 통해 이루어지기 때문에 matplotlib.pyplot을 plt로 선언하는 겁니다. matplotlib을 plt로 사용한다면 pyplot의 함수를 사용할때 plt.pyplot.함수() 형태로 이루어져야 합니다.
import matplotlib.pyplot as plt
plt 객체를 설정해 다음과 같이 출력할 수 있습니다.
x= df['Names']
y = df['Births']
plt.bar(x,y) # 막대 그래프를 구성하는 값 입력/막대그래프 객체 생성
plt.xlabel('Names') # x축 제목
plt.ylabel('Births') # y축 제목
plt.title('Bar plot') # 그래프 제목
plt.show() # 그래프 출력
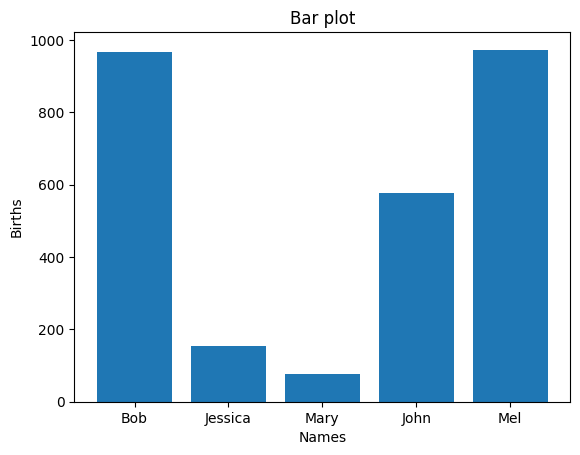
plt 객체를 설정해 다음과 같이 출력할 수 있습니다.
# 랜덤 추출 시드를 고정합니다.
np.random.seed(19928613)
# 0부터 100까지 5단위로 증가하는 배열을 생성합니다.
x = np.arange(0.0, 100.0, 5.0)
# 산점도 데이터를 생성합니다.
# y 값은 x 값에 1.5를 곱하고, 랜덤한 노이즈를 추가합니다.
y = (x * 1.5) + np.random.rand(20) * 50
# 산점도 데이터를 출력합니다.
# c는 점의 색상을 지정합니다. 'b'는 파란색을 나타냅니다.
# alpha는 점의 투명도를 지정합니다. 0.5는 반투명을 나타냅니다.
# label은 그래프의 범례에 표시될 텍스트를 지정합니다.
plt.scatter(x, y, c='b', alpha=0.5, label='scatter point')
# x 축과 y 축에 레이블을 추가합니다.
plt.xlabel('X')
plt.ylabel('Y')
# 그래프의 범례를 좌상단에 표시합니다.
plt.legend(loc='upper left')
# 그래프의 제목을 설정합니다.
plt.title('Scatter plot')
# 그래프를 화면에 표시합니다.
plt.show()
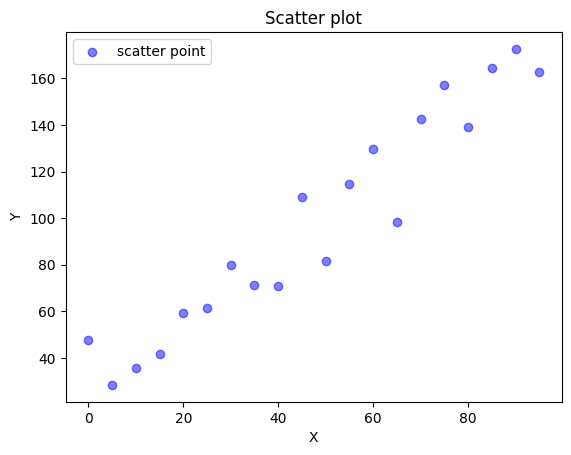
0장 들어가며에서는 간략한 환경 구축 및 넘파이, 판다스, 맷플롯립 맛보기를 하였다.
댓글