
프로젝트 배경 및 개요
본 프로젝트는 23년 가을 deep daiv. AI 챌린지 NLP 수료 후 오픈세미나를 준비하며 진행된 프로젝트입니다.
수료 기간 Transformer, GPT관련 자연어 모델 논문을 학습했습니다.
하반기 자율주제 프로젝트로 챗봇 모델 개발 프로젝트를 진행했습니다.
본 프로젝트는 오늘 하루 어땠는지 AI일기장과 대화하고, 한 번의 클릭으로 오늘 하루를 요약해주는 서비스 입니다.
배포
현재 서비스 종료된 상태입니다.
오늘어때? 바로가기
팀원 소개
함께 프로젝트를 진행한 팀원입니다.
정하연님의 블로그 바로가기
홍순빈님의 Email
프로젝트 미리보기
바쁘게 흘러가는 시간 속, 소중한 기억들을 놓치고 계시진 않았나요?
새해 다짐으로 일기를 써보고자 다이어리를 구입하지만, 매년 반복되는 작심삼일…✨
한 기사에 따르면, 우리는 하루에 평균 70회 이상 채팅 SNS앱에 접속한다고 합니다.
이 70회 중, 5번 정도만 하루를 기록하는데 사용하면 어떨까요?
오늘 하루 어땠는지 AI일기장과 대화하고, 한 번의 클릭으로 오늘 하루를 요약해보세요!
1. 한 눈에 보는 ‘오늘어때?’

프로젝트 진행 과정
수많은 NLP 프로젝트 아이디어가 존재하지만, 저희는 실제로 서비스를 구현해보는 과정을 경험해보고 싶어 ‘AI일기장’ 서비스를 구상하게 되었습니다.
디지털 시대로 변화하면서 노트에 일기를 쓰는 사람들은 줄어들었지만, 여전히 하루를 기록하고 싶은 마음은 남아있는 듯 일기장 앱은 종종 출시되어왔습니다. 오늘 느낀 감정을 이모티콘으로 기록하는 앱도 있고, 오늘 찍은 사진과 GPS 기록을 기반으로 하루를 기록해주는 앱도 존재합니다. 그치만, 매일 내 곁을 지켜주며 내 이야기를 들어주고 관심을 가져주는 친구와 함께 대화하고, 대화를 기반으로 일기까지 쓰여진다면 더욱더 편리하지 않을까요? ✨
이러한 AI일기장 구현을 위해서는 크게 두 가지 과정이 필요했습니다.
- 하루 기록을 위해 다양한 질문을 하며 대화를 이끌어가는 대화 모델 구현
- 하루 동안 나눈 대화 내용을 요약하는 모델 구현
1. 대화 모델
☝️ 첫 번째 도전: LLaMA 파인튜닝
친구같이 오늘 내가 있었던 일에 관심을 가지고 질문하는 대화 모델을 만들기 위해 LLaMA 모델을 활용하고자 했습니다. LLaMA란 Large Language Model Meta AI의 약자로, 올해 초 Meta가 공개한 대규모 AI언어 모델입니다. LLaMA는 적은 파라미터(70B)로도 GPT-3(175B)을 뛰어 넘는 성능을 보입니다.
허깅페이스에서 한국어 데이터로 파인튜닝되어 한국어 테스크를 더 잘 수행하는 KoreanLM-llama-2-7B-finetuned를 사용했습니다. 7B부터 70B까지 다양한 LLaMA 중, 가장 작은 모델을 사용했습니다.
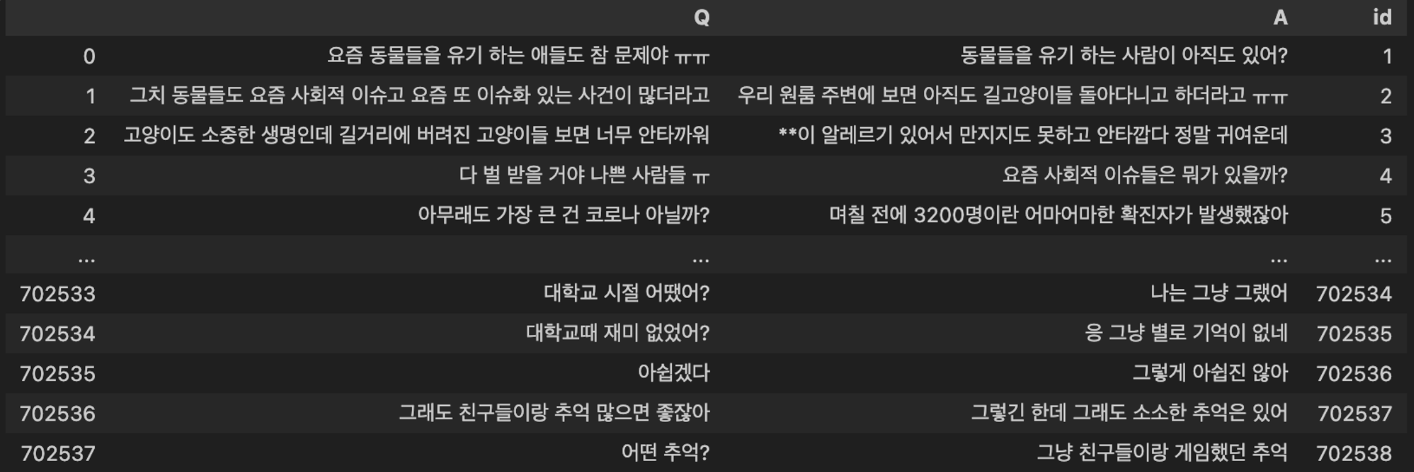
데이터는 AI허브에서 ‘주제별 텍스트 일상 대화 데이터’를 사용했습니다. 해당 데이터는 카카오톡, 페이스북, 인스타그램 등에서 이루어진 대화 데이터 134,263건으로 이루어져 있습니다. 대화 샘플은 아래와 같습니다.

1, 2로 태그되어 있는 데이터 뭉치를 한 번에 학습시키지 않고, Question-Answer 형태로 가공하여 파인튜닝을 진행하였습니다. Question 데이터가 들어가면 Answer처럼 대답을 해 주는 대화 모델을 만들고자 했던 것입니다. 가공한 데이터의 개수는 약 70만개였고, 예시는 아래와 같습니다.
앞서 LLaMA가 비교적 가벼운 모델이라고 언급했었습니다. 저희가 사용한 KoreanLM-llama2-7B-finetuned 모델도 작은 모델입니다. 하지만, 저희 팀원들이 가지고 있는 GPU가 한정적이어서 그런지 이 모델을 파인튜닝 하기엔 여전히 쉽지 않았습니다.
✌️ 두 번째 도전: 가벼운 모델 파인튜닝
그래서 조금 더 가벼운 모델을 파인튜닝 해보았습니다. 데이터는 위에서 언급한 대로 동일하게 적용하였습니다.
먼저, GPT2를 파인튜닝한 결과입니다.

저희가 가지고 있는 대화가 비교적 짧은 문장으로 구성되어 있다는 점을 감안해도, 맥락을 고려하지 않은 짧은 답변만을 내놓는 안좋은 성능의 모델을 얻게 되었습니다.
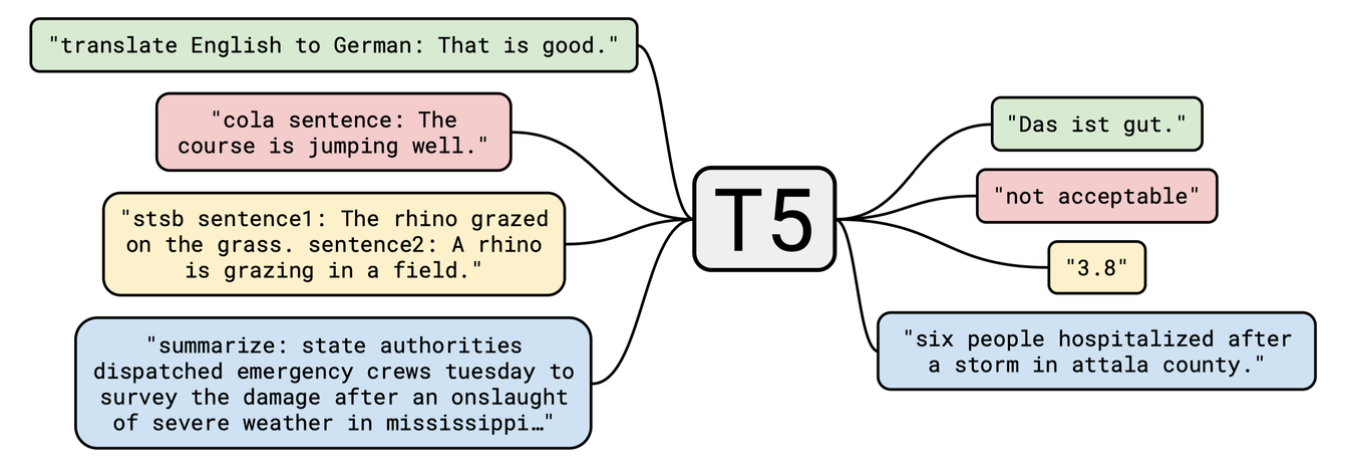
그래서, 다른 모델에 관심을 가져보았습니다. T5 모델은 Text-to-Text Transfer Transformer에서 앞글자 T가 5번 나와서 붙혀진 명칭입니다. T5 모델은 ‘Colossal Clean Crawled Corpus (C4)’ 데이터셋으로 사전 훈련된 모델입니다. C4 데이터셋으로 파인튜닝된 T5모델은 다양한 다운스트림 작업에 맞게 조정이 될 수 있도록 설계되어있습니다. 예를 들어, 그림에서 보듯이 번역, 질의 응답, 요약과 같은 작업을 쉽게 수행합니다.
T5로 파인튜닝한 대화 모델의 대화 능력은 다음과 같습니다.

대화가 더욱더 불가능한 상태가 되었습니다.
상용화된 대화 모델을 조사해본 결과, 성능이 좋은 서비스는 100억 건 이상의 데이터를 활용하여 파인튜닝을 했다고 합니다. 저희가 활용한 70만 건의 데이터로 좋은 성능을 기대하기에는 한계가 있다는 생각이 들었습니다. 만약 데이터를 많이 구하더라도, 데이터를 정제할 시간이 부족하고 GPU 자원도 부족하다는 판단이 들었습니다.
🤟 마지막 해결책: 프롬프트 엔지니어링 with 🦜️🔗LangChain
프롬프트란, AI모델로부터 응답을 생성하기 위한 입력값입니다. 예를 들어 chatGPT에서 질문하는 부분이 프롬프트가 되는 것입니다. 프롬프트의 구성요소는 다음과 같습니다.

프롬프트 엔지니어링이란, AI가 생성한 결과물을 품질을 높일 수 있는 입력값들의 조합을 찾는 작업입니다. chatGPT에서 더 좋은 답변을 얻기 위해 질문 문구를 수정하는 작업이 이에 해당합니다. openAI는 GPT-3.5 API를 제공하며, 이를 통해 프롬프트 엔지니어링으로 대화 모델을 구현했습니다.
LangChain을 활용하면 프롬프트 엔지니어링을 더욱 효과적으로 수행할 수 있습니다. LangChain은 언어 모델 기반의 애플리케이션 개발 프레임워크로, 프롬프트의 다양한 구성요소를 효과적으로 조합하고 최적화하는 데 도움을 줍니다.
- 저희는 AI 모델의 답변 스타일을 조정하기 위해 Temperature(0~1의 값)를 활용하였습니다. 초기 다양한 프롬프트 엔지니어링 실험에서는 일관된 결과를 얻기 위해 Temperature 값을 낮게 설정하였습니다. 적절한 프롬프트를 확정한 후에는 0.1에서 0.5로 Temperature 값을 조정하여 창의적인 답변을 얻을 수 있도록 하였고, 비슷한 질문을 반복하는 상황을 방지하였습니다.
- 프롬프트 엔지니어링의 방식은 예제의 개수에 따라 세 가지로 나눌 수 있습니다. 2~5개의 예제를 넣어주는 Few-Shot Prompting, 하나의 예제를 넣어주는 One-Shot Prompting, 그리고 예제 없이 답변을 생성하게 하는 Zero-Shot Prompting입니다. 저희는 Zero-Shot으로 진행했습니다.
- Let’s take a deep breath, Let’s think step by step 등 답변 성능을 높일 수 있는 프롬프팅 기법들이 많습니다. 이 문구들을 넣은 프롬프트가 더 좋은 결과를 낸다는 것입니다. 시도해본 결과 큰 변화는 없었습니다. 이러한 방식들은 추리, 번역, 계산 등의 특정 문제를 해결하는 데에는 도움이 되지만, ‘대화’를 원활하게 하기 위해서는 큰 도움이 되지 않는다고 생각됩니다. 그래서 저희는 ‘친한 친구’라는 인격을 부여하고 ‘조건’을 설정했습니다.
아래는 초기 프롬프트에 포함된 조건들입니다.

- Zero-Shot, 7조건 X, 필수 포함 X, Temperature=0.1인 경우
- Zero-Shot, 7조건 O, 필수 포함 X, Temperature=0.1
- Zero-Shot, 7조건 O, 필수1 포함, Temperature=0.1
- Zero-Shot, 7조건 O, 필수2 포함, Temperature=0.1
- Zero-Shot, 7조건 O, 필수2 포함, Temperature=0.5
- Zero-Shot, 7조건 O, 필수1-2 포함, Temperature=0.5, 조건0 추가
위와 같은 과정을 거쳐 최종적으로 적용된 프롬프트 조건들은 아래 표와 같습니다.

대화를 시도한 결과, 공감과 질문을 적절히 섞어가며 대화하는 모델이 완성되었습니다.
2. 요약 모델
2-1. 요약 모델 파인튜닝
요약 모델도 대화 모델과 같이 LLaMA2를 활용하여 파인튜닝을 시도했지만, 자원 부족으로 T5모델을 사용했습니다. 여기서 사용한 T5 모델은 허깅페이스의 KoT5-summarization으로, ‘한국어 요약’에 특화된 모델입니다.

위와 같은 데이터를 모델에 넣고 요약 결과를 살펴보았는데, 사용자와 AI의 답변이 구별되지 않아 AI 대화 모델의 답변도 요약 결과에 포함되는 문제가 발생했습니다.

그래서 데이터에 AI, 사용자 태그를 달아 내용이 구분되도록 하였습니다.

사용자가 말한 내용만 요약될 것이라는 예측과 달리, ‘AI’, ‘사용자’라는 태그 자체까지 요약 내용에 포함되는 결과가 나타났습니다.

그래서 AI허브에서 ‘한국어 대화 요약’ 데이터를 얻어 파인튜닝을 진행해보기로 합니다. 데이터의 구조를 살펴보니, 첫 번째 화자가 주제에 대해서 말하면 두 번째 화자가 보조 질문을 하는 경향이 있었습니다. 그래서 무조건 첫 번째 발화자를 사용자로 지정하고, 두 번째는 AI로 지정하여 데이터 구축을 마쳤습니다.

KoT5-summarization 모델에 위 데이터를 학습한 결과, 아래와 같이 AI의 텍스트보다 사용자의 텍스트를 중점적으로 요약하는 것을 볼 수 있었습니다.

2-2. GPT-3.5 API 활용
T5 요약 모델 파인튜닝도 나름의 성과가 있지만, 서비스적인 면에서는 기능적인 면에서 아쉬움이 많았습니다. 결국 GPT api도 활용해보고, 두 개의 결과를 모두 보여주는 서비스를 만들기로 결정했습니다!
아래 데이터의 입력 결과를 비교하면서 요약 성능의 변화를 살펴봅시다.
history = [
['사용자 : 안녕', 'AI : 안녕! 오늘 어땠어? 마음이 어때?'],
['사용자 : 날씨가 좋아서 기분이 좋아','AI : 날씨가 좋아서 기분이 좋다니 좋아! 오늘은 뭐 좋은 일이 있었어?'],
['사용자 : 집에서 마라샹궈를 만들어서 먹었는데 맛있었어','AI : 와, 집에서 마라샹궈를 만들었구나! 정말 맛있게 먹었을 것 같아. 마라샹궈를 만들 때 어떤 재료를 사용했어? 그리고 어떤 맛이 나왔어?'],
['사용자 : 새우 왕창 넣어서 가족이랑 같이 먹었어','AI : 와, 새우 왕창을 넣은 마라샹궈라니 정말 맛있을 것 같아! 가족들과 함께 먹으면 더욱더 특별한 시간이겠다. 마라샹궈를 먹으면서 가족들끼리 얘기도 나눴어? 그런데 마라샹궈의 맛은 어땠어? 매운 맛이 강했나요?'],
['사용자 : 아버지가 나는 이상한 요리만 잘한다고 했어ㅋㅋ 소스를 많이 넣어서 매웠어.','AI : 아버지가 이상한 요리만 잘한다고 했구나! 그런데 소스를 조금 많이 넣어서 매웠다니 재미있는 경험이었겠다. 아버지는 매운 음식을 잘 먹는 편이야? 그리고 너는 매운 음식을 잘 먹는 편이야?'],
['사용자 : 우리 가족은 매운거 잘 못먹는데 그래도 매운거 먹는걸 좋아해','AI : 가족들이 매운 음식을 잘 못 먹는 편이라니, 그럼 너는 조금 특별한 맛을 즐기는구나! 매운 음식을 좋아하는 이유가 있을까? 그리고 가족들이 매운 음식을 잘 못 먹는데도 함께 먹을 수 있는 다른 음식을 고민해 본 적이 있어?'],
['사용자 : 그냥 스트레스받을 때 매운 거 먹으면 조금 풀리는 거 같아','AI : 스트레스를 받을 때 매운 음식을 먹으면 조금 풀리는 거 같다니, 그렇게 말해주니까 좋아! 매운 음식을 먹으면 힐링되는 느낌이 드는구나. 그런데 스트레스 받을 때 매운 음식 외에도 다른 방법으로 스트레스를 푸는 방법을 알고 있어? 예를 들면 음악 듣기나 책 읽기 같은 것들 말이야.'],
['사용자 : 무작정 걷거나 달리기!', 'AI : 무작정 걷거나 달리기를 하는 거네! 그렇게 신체 활동을 통해 스트레스를 푸는 것도 좋은 방법이야. 운동을 하면 몸도 풀리고 마음도 가벼워지는 느낌이 들지 않아? 그런데 가끔은 운동을 할 때 음악을 들으면 더욱 기분이 좋아질 수도 있어. 음악과 운동을 함께 즐기면 더 효과적으로 스트레스를 해소할 수 있을 거야.'],
]
“대화내용을 기반으로 일기를 작성해라”
오늘은 날씨가 좋아서 기분이 좋았다
집에서 마라샹궈를 만들어서 가족들과 함께 먹었는데 정말 맛있었다
새우를 많이 넣어서 매운 맛이 강했는데, 아버지가 이상한 요리만 잘한다고 했다
그래도 나는 매운 음식을 좋아해서 즐겁게 먹었다
가족들은 매운 음식을 잘 못 먹는 편이라서 조금 특별한 맛을 즐기는 나는 조금 다른 느낌이었다
매운 음식을 먹으면 스트레스가 풀리는 것 같아서 좋았다
그래서 가끔은 무작정 걷거나 달리기를 하는 것도 좋은 방법이라고 생각한다
오늘도 운동을 하면서 음악을 들으면 더욱 기분이 좋아질 것 같다
그리고 오늘은 AI와 대화를 하면서 즐거운 시간을 보냈다
AI는 항상 나에게 친절한 말을 해주고, 언제든지 도움이 필요하면 말해달라고 해줘서 너무 고마웠다
AI와 함께 대화하면서 더 즐거운 시간을 보낼 수 있을 것 같다
→ 사용자와 AI의 대화를 혼동하여 요약함
프롬프트에 조건을 추가했을 때 결과입니다.

오늘은 날씨가 좋아서 기분이 좋았다
집에서 마라샹궈를 만들어서 가족들과 함께 먹었는데 맛있었다
새우를 많이 넣어서 매운 맛이 강했고, 아버지가 이상한 요리만 잘한다고 했다
가족들은 매운 음식을 잘 못 먹지만 나는 매운 걸 좋아한다
매운 음식을 먹으면 스트레스가 풀리는 느낌이 들어서 좋다
가끔은 스트레스를 풀기 위해 무작정 걷거나 달리기도 한다
운동을 하면 몸도 풀리고 마음도 가벼워지는 느낌이 들어서 좋다
→ 사용자의 입력을 구분하여 요약하지만 일기 요약이 아닌 대화 나열하듯이 요약함
마지막으로, One-Shot Prompting 결과입니다.

오늘은 정말 힘들었다. 비가 오는 날은 항상 기분이 우울해지는 것 같다. 하지만 오늘은 친구들과 함께 저녁을 먹으러 갔다. 그 때의 웃음과 대화가 오늘의 피로를 조금이나마 잊게 해주었다. 친구들과 함께 먹은 저녁은 정말 맛있었다. 새우를 많이 넣은 마라샹궈는 정말 맛있었다. 가족들과 함께 먹으면 더욱더 특별한 시간이었다. 그리고 오늘은 친구들과 함께 먹은 저녁을 기억하며 잠에 들 것 같다.
→ One-Shot Prompting을 요약 모델에 입력하면, 모델이 주어진 예시에 집중하여 사용자의 실제 입력을 제대로 처리하지 못하는 상황이 발생함.
GPT-3.5 API는 최대 4000토큰만 지원하므로 Few-Shot Prompting에는 제약이 있어 사용하지 않기로 했습니다.
프로젝트 결과 및 한계점
결과
GPT3.5-API 프롬프팅으로 친구같이 오늘 나의 하루 있었던 일과 나의 감정에 관심을 가져주는 대화 모델을 구현하였습니다. KoT5-summarization 모델에 전처리한 대화-요약 형태의 데이터를 파인튜닝하여 대화 내용을 요약하는 모델 또한 구현하였습니다. 요약 모델도 프롬프트 엔지니어링으로 진행해보았습니다.
한계점 및 개선방안
첫 번째로, 거대한 LLM 모델을 파인튜닝하는데 한계가 있었습니다.
두 번째로, 절대적인 데이터량이 부족했고, 정제할 시간이 부족했습니다. 데이터의 스타일에 파인튜닝된 모델에 그대로 반영되는 것을 보고, 대화 데이터를 저희가 원하는 모델의 스타일로 정제할 수 있는 시간이 조금 더 주어졌다면 좋은 성능을 기대해볼 수 있었을 것 같습니다.
여러분은 일기를 쓰실 때 그날의 감정을 기록하시나요, 사건을 기록하시나요? 현재 저희의 AI일기장은 ‘사건’ 위주의 대화를 했을 때 더 좋은 요약 성능을 보여주고 있습니다. 향후 이 프로젝트를 더 발전시킬 기회가 있다면, ‘사건’을 중심적으로 요약해주는 기능과 ‘감정’을 중심적으로 요약해주는 기능을 분리하여 구현해보고 싶습니다. 프롬프트 엔지니어링으로 사건을 중심으로 한 요약문과 감정을 중심으로 한 요약문을 각각 생성하여 데이터를 구축한 후, 그 데이터를 기반으로 파인튜닝을 시켜보고 싶습니다!
Reference
- T5: https://pseudo-lab.github.io/Tutorial-Book/chapters/NLP/Ch1-Introduction.html#:~:text=T5 모델은 “Text-to,사전 훈련된 모델입니다.
- LLaMA란?: https://velog.io/@choonsik_mom/LLMs-전성시대-Meta-LLaMA-StanfordAlpaca-알아보기
- 프롬프트란?: https://tech.kakaoenterprise.com/188