GPT-1 논문 리뷰 - "Improving Language Understanding by Generative Pre-Training"

∣
2023년 8월 7일


자연어의 이해에 관한 내용과 현재 학습 시스템의 문제점을 제시하며 GPT 모델의 특징을 말하고 있다.

Abstract에서 말했던 라벨링 안된 데이터에 관한 단점과 라벨링이 안된 데이터를 학습 가능할 때 장점에 대한 이야기이다.

라벨링 안된 데이터를 활용한 학습이 단어 수준 이상의 정보를 활용하는 것에 어려운 이유를 설명한다.

GPT의 목표는 광범위한 작업에 거의 적응하지 않고 이전하는 보편적인 표현을 배우는 것이라고 한다. 추가적으로 두 단계의 절차를 거처 교육을 한다고 한다.

GPT는 Transformer의 아키텍처를 사용했다고 한다. 트랜스포머 모델을 선정한 이유에 대해서 말한다.

논문은 GPT 모델을 아래 4가지 유형으로 평가하겠다고 한다. 그리고 실적을 자랑한다.

GPT 연구는 Semi-supervised Learning(반지도 학습)에 포함된다고 한다.
지난 몇 년 동안 연구원들은 라벨이 부착되지 않은 말뭉치에 대해 훈련된 단어 임베딩을 사용하여 다양한 작업에 대한 성능을 향상시키는 이점을 입증했다고 한다 그러나 이러한 접근 방식은 주로 단어 수준의 정보를 전달하는 반면, 우리는 더 높은 수준의 의미론을 포착하는 것을 목표로 한다고 한다.

비지도 사전 훈련(Unsupervised pre-training)은 지도 학습 목표를 수정하는 대신 좋은 초기화 지점을 찾는 것인, 반지도 학습의 특별한 경우라고 한다.

자연어 처리(NLP) 분야에서 반지도 학습을 개선하는 방법으로서 보조 비지도 훈련 목표를 사용하는 것에 대한 관련 연구에 대해서 말한다.
추가적으로 본 실험은 또한 auxiliary objective(보조 목표)를 사용하지만, 추가적인 보조 목표의 사용 없이도 비지도 사전 훈련이 이미 언어 처리 작업에 필요한 언어적 특징을 학습하고 있다고 말한다.

지속적으로 학습을 두단계에 걸쳐 진행한다고 안내한다.

주어진 레이블이 없는 토큰 코퍼스 U = {u1, . . . , un}에서, 다음과 같은 표준 언어 모델링 목표를 최대화하기 위한 이야기이다.
예시를 들어보자면 아래와 같은 학습 데이터가 있다고 하자
1. A: "오늘 날씨 정말 좋아요."
2. B: "맞아, 햇살이 환하게 비치고 있어요."
3. A: "날씨가 좋으니 나가서 놀러 다녀야겠어요."
4. B: "이미 나는 오늘 밖에 놀러 나왔어어."
그렇다면 주어진 문장 4번에 대해서 아래와 같이 학습할 수 있다.
“ 나는 오늘 밖에 ___ “를 예측 한다.
| P(“놀러” | “이미 나는 오늘 밖에”) = P(ui | ui−k, …, ui−1; Θ) |
문맥 윈도우는 “이미 나는 오늘 밖에”이며 현재 단어는 “날씨가”와 “놀러”가 될 수 있다.
즉 모델은 문맥 윈도우에 기반하여 현재 단어 “날씨가”가 나올 확률, “놀러”가 나올 확률 P(ui | ui−k, …, ui−1; Θ)를 학습하게 된다.

실험에서는 언어 모델을 위해 다중 레이어 트랜스포머 디코더를 사용했는데, 이는 트랜스포머의 변형이라고 한다.
모델은 입력 문맥 토큰 위에 다중 헤드 셀프 어텐션 연산을 적용하고 이어서 위치별 피드포워드 레이어를 사용하여 대상 토큰에 대한 출력 분포를 생성한다.
예시를 들어보자면 아래와 같은 학습 데이터가 있다고 하자
예시 문장: "이미 나는 오늘 밖에"
현재 단어: "날씨가"

문장 내에서 다음 단어를 예측하는 언어 모델링과 같은 사전 훈련 작업을 마친 후에, 주어진 레이블된 데이터를 활용하여 해당 작업에 맞게 예측 모델을 조정한다고 한다. 추가 보정 작업을 통해 모델은 더 많은 언어적 특성과 문맥 정보를 학습할 수 있게 되며, 이런 추가 정보를 활용하면 모델의 수렴 속도가 빨라진다고 한다.

입력 토큰들 x1, …, xm으로부터 예측 확률 P(y)를 계산하는 방법을 보여준다. 레이블이 지정된 데이터 세트 C를 가정한다. 여기서 각 인스턴스는 레이블 y와 함께 입력 토큰 시퀀스인 x1, …, xm으로 구성된다. 입력은 사전 훈련된 모델을 통해 최종 transformer block의 활성화 hml을 얻은 다음 매개 변수 Wy로 추가된 선형 출력 계층에 입력되어 예측된다고 한다.
예시 문장: "나는 자연어처리가 정말 좋아요"
# 문장 분류 작업으로 긍정과 부정을 나타내는 라벨링이 있다고 가정
따라서 이 예시에서 P(y)를 계산하는 수식인 P(y|x1,…,xm) = softmax(hml Wy)는 주어진 입력 문장의 토큰들로부터 해당 문장이 긍정인지 부정인지를 예측하는 데 사용되는 확률 분포를 나타낸다.
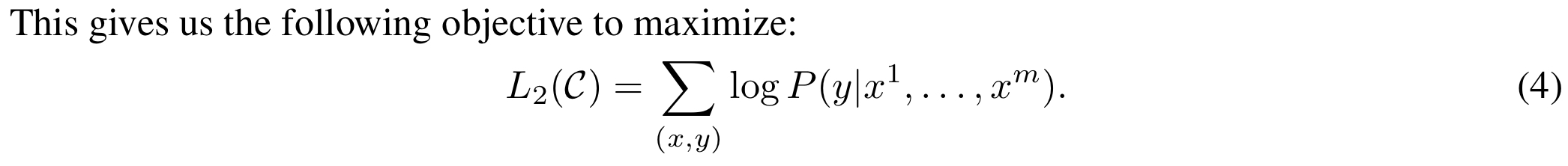

L3(C)는 L2(C)와 λ * L1(C)를 합산한 것으로, 모델을 보조 목표와 주된 목표 모두를 동시에 최적화하도록 돕는다.
문장 1: "자연어 처리는 정말 재미있어요." (긍정)
문장 2: "자연어 처리는 너무 지루해요." (부정)
문장 3: "자연어 처리는 뭐하는 건지 모르겠어요." (부정)
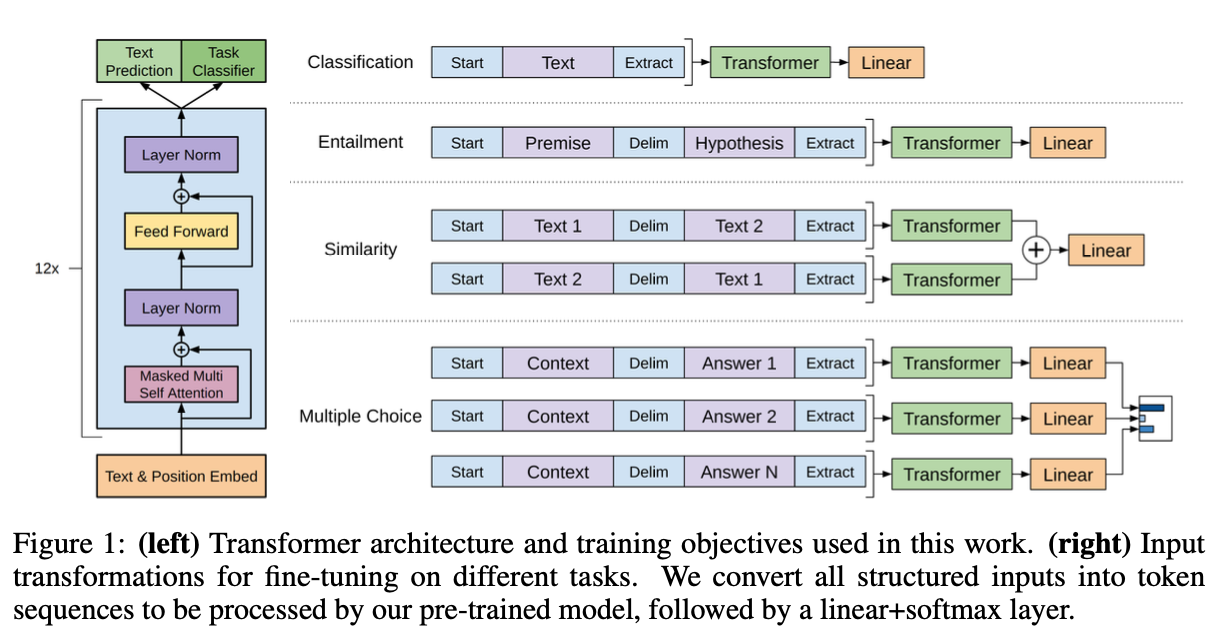
왼쪽 그림 (Transformer 아키텍처와 훈련 목적):
Transformer 아키텍처와 연구에서 사용된 훈련 목적을 보여준다. Transformer 아키텍처는 입력 문장을 처리하고 특징을 추출하는데 사용되며, 이를 통해 언어 모델링과 다른 자연어 처리 작업을 수행할 수 있다. 왼쪽 그림은 이러한 Transformer 아키텍처의 개략적인 형태를 나타낸다.
오른쪽 그림 (다양한 작업에 대한 미세 조정을 위한 입력 변환):
이 부분에서는 다양한 작업에서 미세 조정을 위해 입력을 어떻게 변환하는지 보여준다. 모든 구조화된 입력은 토큰 시퀀스로 변환되어 사전 훈련된 모델에서 처리된다. 이 변환은 입력 데이터를 모델이 이해할 수 있는 형태로 바꿔주는 역할을 한다. 그리고 선형+소프트맥스 레이어가 추가되어 예측 결과를 생성한다.

이전 연구에서의 접근 방법에 대한 단점과 본 논문에서 제시하는 traversal-style approach(횡단 스타일 접근법)에 대한 이야기이다.
구조화된 입력: ("자연어 처리 재미있어?", "응! 조금 재미있어!")
문장1 변환: ["⟨s⟩", "자연어", "처리는", "재미있어", "?", "⟨e⟩"]
문장2 변환: ["⟨s⟩", "응", "!", "조금", "재미있어", "!", "⟨e⟩"]
시퀀스: ["⟨s⟩", "자연어", "처리는", "재미있어", "?", "⟨e⟩", "⟨s⟩", "응", "!", "조금", "재미있어", "!", "⟨e⟩"]
이 변환된 입력 시퀀스를 모델에 주입하여 텍스트 추론 작업을 수행할 수 있다. 이렇게 하나의 입력 시퀀스로 변환하는 과정을 통해 모델은 구조화된 입력을 처리하고 해당 작업을 수행할 수 있게 된다.

텍스트 추론 작업에서는 전제(premise)와 가설(hypothesis)의 관계를 판단하는 것이 목표이다. 전제와 가설을 합친 시퀀스($ 토큰으로 구분)를 모델에 입력으로 제공하여 텍스트 추론 작업을 수행해 모델은 이 합쳐진 시퀀스를 바탕으로 전제와 가설 사이의 추론 관계를 예측하거나 분류하는 데 활용한다.
전제 (premise): "고양이는 동물이다"
가설 (hypothesis): "고양이는 움직일 수 있다"
합쳐진 시퀀스: ["고양이는", "동물이다", "$", "고양이는", "움직일", "수", "있다"]
관계 : Entailment (수반 관계)
전제 (premise): "고양이는 동물이다"
가설 (hypothesis): "고양이는 식물이다"
합쳐진 시퀀스: ["고양이는", "동물이다", "$", "고양이는", "식물이다"]
관계 : Contradiction (모순 관계)
전제 (premise): "나는 오늘 밖에 나갔다"
가설 (hypothesis): "나는 집에 있다"
합쳐진 시퀀스: ["나는", "오늘", "밖에", "나갔다", "$", "나는", "집에", "있다"]
관계 : Neutral (중립 관계)

유사성 작업의 경우 비교되는 두 문장의 고유한 순서가 없다. 이를 반영하기 위해 입력 시퀀스를 수정하여 가능한 문장 순서를 모두 포함하고(그 사이에 구분 기호가 있음) 각각 독립적으로 처리한다. 선형 출력 계층으로 공급되기 전에 요소 단위로 추가되는 두 개의 시퀀스 표현 hml을 생성한다.
입력: 두 개의 문장 ("나는 자연어 처리를 좋아해", "나는 너무 재미있어")
문장1 시퀀스 : ["⟨s⟩", "나는", "자연어", "처리를", "좋아해", "⟨e⟩"]
문장2 시퀀스 : ["⟨s⟩", "나는", "너무", "재미있어", "⟨e⟩"]
변환된 입력 시퀀스 1: ["⟨s⟩", "나는", "자연어", "처리를", "좋아해", "⟨e⟩", "$", "나는", "너무", "재미있어", "⟨e⟩"]
변환된 입력 시퀀스 2: ["⟨s⟩", "나는", "너무", "재미있어", "⟨e⟩", "$", "나는", "자연어", "처리를", "좋아해", "⟨e⟩"]
하나의 입력 시퀀스에 하나의 hml (sequence representation)을 생성한다. 두 hml 벡터는 요소별로 더해져서 문장 간의 유사도를 나타내는 최종 특성 벡터가 생성

Question Answering”과 “Commonsense Reasoning”이라는 작업 유형에 대한 설명이다.
예를 들어 아래와 같은 구조의 시퀀스를 만들 수 있다.
문맥 문서(z): "한국은 동아시아의 한 반도에 위치한 나라입니다."
질문(q): "한국의 수도는 어디인가요?"
가능한 답변: {"서울", "도쿄", "뉴욕"}
아래 생성될 수 있는 입력 시퀀스이다.
[한국은 동아시아의 한 반도에 위치한 나라입니다.;한국의 수도는 어디인가요?;$;서울]
[한국은 동아시아의 한 반도에 위치한 나라입니다.;한국의 수도는 어디인가요?;$;도쿄]
[한국은 동아시아의 한 반도에 위치한 나라입니다.;한국의 수도는 어디인가요?;$;뉴욕]
[z;q;$;”서울”], [z;q;$;”도쿄”], [z;q;$;”뉴욕”]으로 학습이 이루어지며 학습되는 데이터의 정보에 따라 정답이 결정된다. 데이터가 텍스트간 관계성에서 뉴욕이 많약 더 많다면 확률적으로 뉴욕이 이란 단어가 나올 확률이 높아지기 때문에 답변은 뉴욕으로 나온다.
실험에 관련된 파트이다.



자연어 추론, 질문 응답, 의미 유사성 및 텍스트 분류와 같은 다양한 지도 작업에 대한 실험을 수행한다고 한다. 이러한 일부 작업은 최근에 공개된 GLUE 다중 작업 벤치마크의 일부로 제공되며, 이를 활용한다. 그림 1은 모든 작업과 데이터셋의 개요를 제공한다.

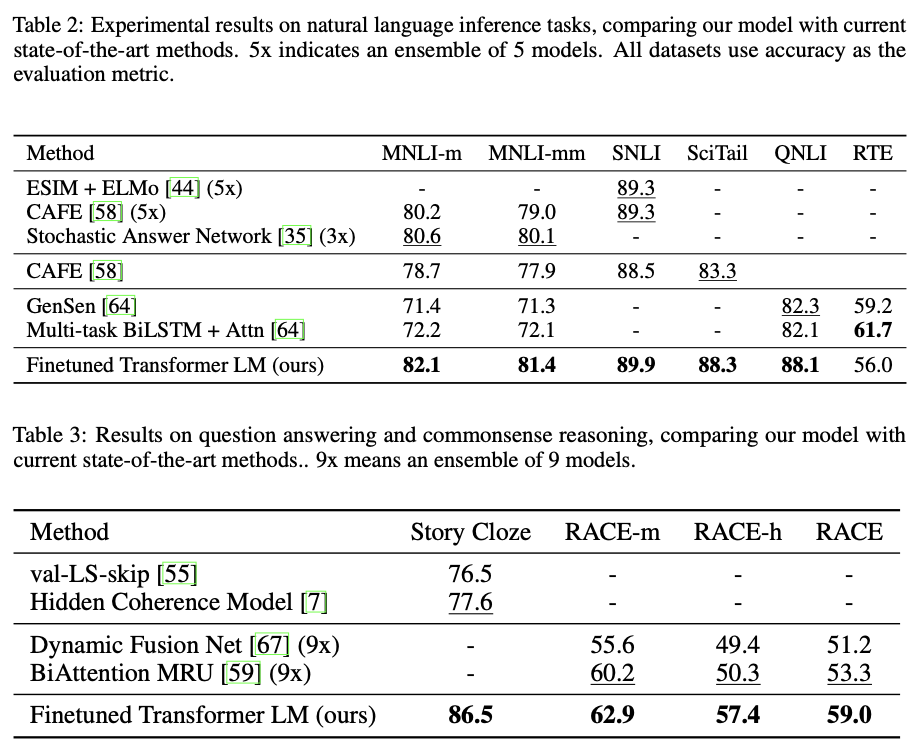
표 2는 우리 모델과 이전 최고 성능 모델에 대한 다양한 NLI 작업 결과를 자세히 설명합니다.

이는 우리 모델이 장거리 문맥을 효과적으로 처리할 수 있는 능력을 보여준다.


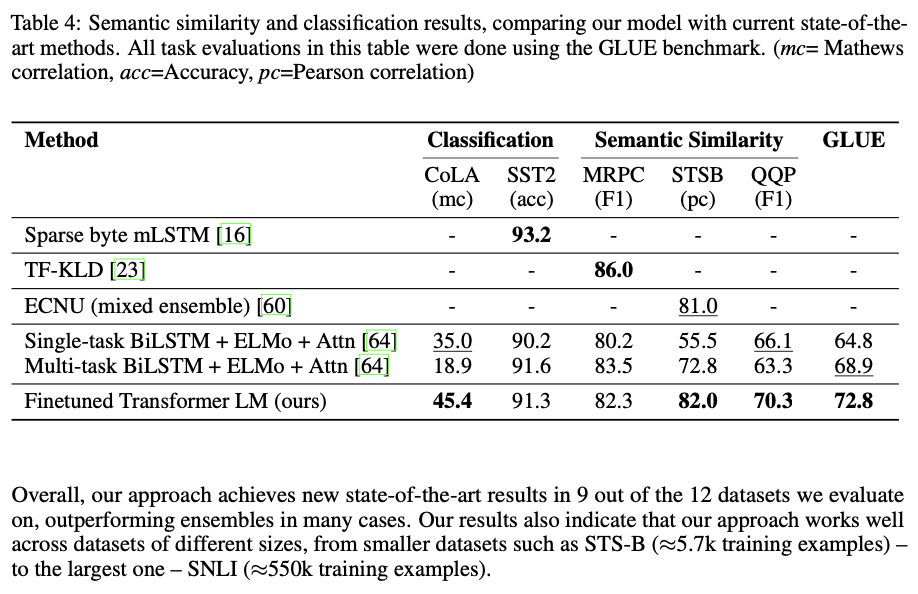
전반적으로, 이 접근 방식은 우리가 평가한 12개의 데이터셋 중 9개에서 새로운 최고 성적을 달성하며, 많은 경우 앙상블을 능가한다.
또한 우리의 결과는 다양한 크기의 데이터셋에서 잘 작동하는 것을 나타낸다.
STS-B (약 5.7천 개의 훈련 예제)와 같은 작은 데이터셋부터 가장 큰 데이터셋인 SNLI (약 55만 개의 훈련 예제)까지 모든 크기의 데이터셋에서 잘 작동한다.
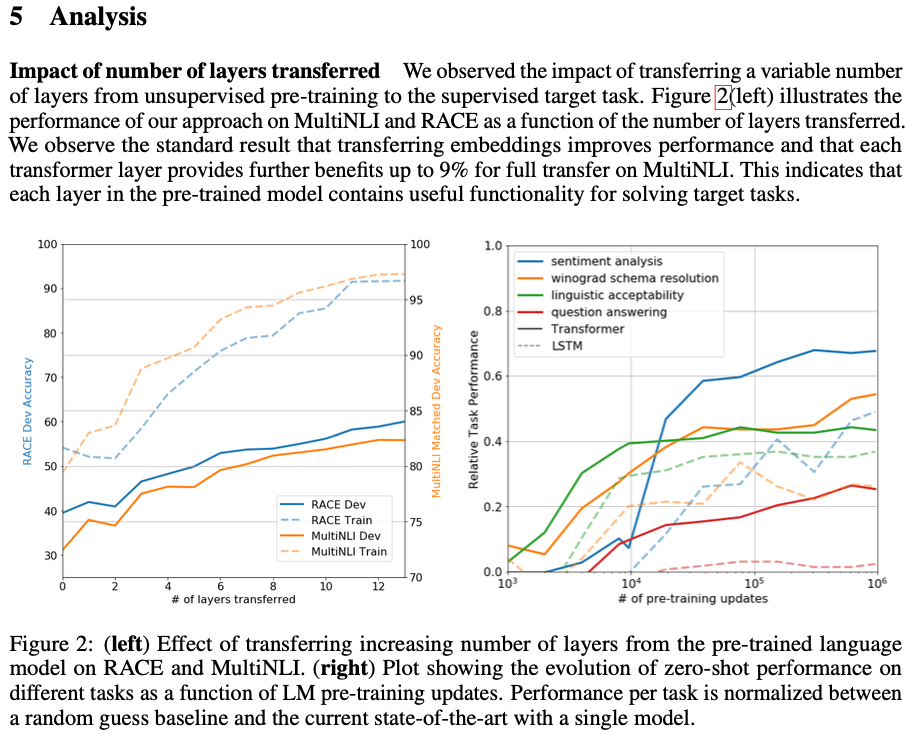
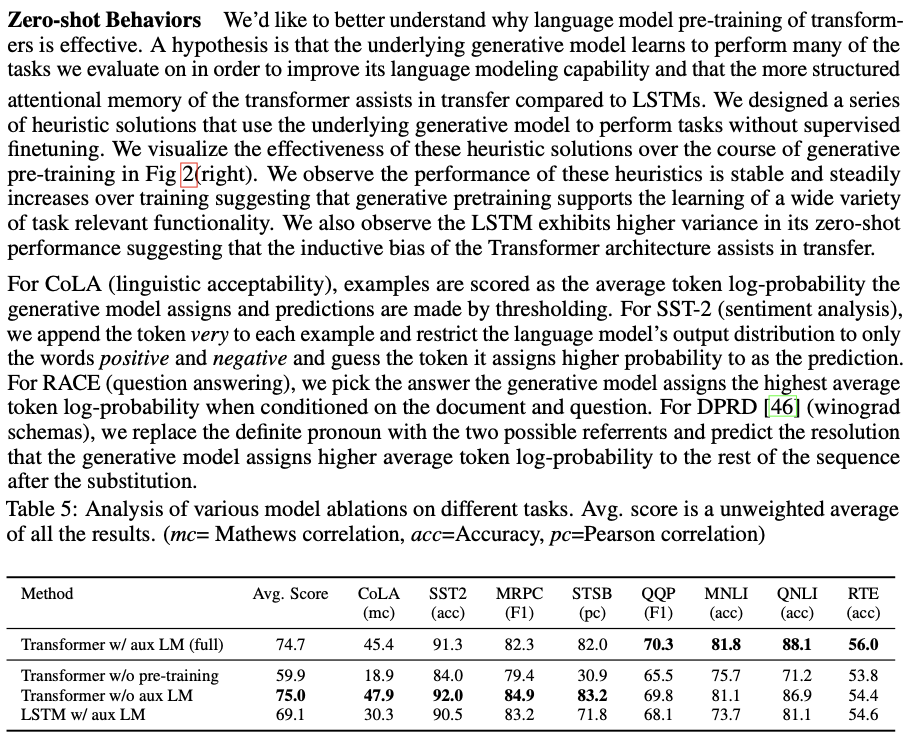
언어 모델 사전 훈련이 왜 효과적인지에 대한 이해를 하고 싶다고 한다.

인공지능에서 분야에서 Ablation studies이란 “machine learning system의 building blocks을 제거해서 전체 성능에 미치는 효과에 대한 insight를 얻기 위한 과학적 실험”으로 정리 될 수 있다고 한다. ([출처] ablation study / 작성자 웃기슈)

단일 태스크에 대한 강력한 자연어 이해를 달성하기 위한 프레임워크를 제시했다.
생성적 사전 훈련과 판별적 미세 조정을 통해 단일 태스크에 대한 모델을 통한다.
긴 연속 텍스트의 다양한 말뭉치에서 사전 훈련함으로써 모델은 중요한 세계 지식과 장거리 종속성 처리 능력을 습득하고, 그런 다음 질문 응답, 의미 유사성 평가, 함의 결정 및 텍스트 분류와 같은 판별적 작업을 해결하는 데 성공적으로 전이된다.
우리는 연구하는 12개의 데이터셋 중 9개에서 성능 향상을 이끌어내며 기술을 제시한다.
(사전)훈련을 사용하여 판별적 작업의 성능을 향상시키는 것은 오래전부터 기계 학습 연구의 중요한 목표 중 하나였다.
저희의 연구는 실제로 중요한 성능 향상을 달성할 수 있다는 것을 시사하며, 이 방법이 가장 잘 작동하는 모델 (Transformer)과 데이터 세트 (장거리 종속성을 가진 텍스트)에 대한 힌트를 제공한다.
이것이 자연어 이해 및 다른 도메인에 대한 비지도 학습 연구로의 새로운 연구를 가능하게 하여 비지도 학습이 언제 어떻게 작동하는지에 대한 우리의 이해를 더 향상시키기를 기대한다!…
gpt1의 중요 포인트는 라벨링을 통한 학습을 조금을 벗어나 문맥 이해가 되는 사전 학습 모델을 만드는 것이 주 포인트 같다. 그 후 특정 테스크에 맞춰진 파인튜닝을 하는 방식이다. 하지만 여전히 파인튜닝이란 방식에서 큰 소비가 있고 한 모델이 멀티테스킹을 하는 것이 어려운 점은 gpt1의 큰 문제 같다. 하지만 gpt란 자체를 이해할 때 가장 근본적으로 기술?적인 부분을 볼 수 있는 논문 같으며 생각보다 흥미롭게 읽었다. 나는 공부하는 것을 별로 좋아하진 않지만… 읽을만 했다… 끝!
댓글