GPT-2 논문 리뷰 - "Language Models are Unsupervised Multitask Learners"

∣
2023년 8월 7일


웹 상의 방대한 텍스트 자료를 활용한 학습은 자연어 처리 작업들에서 지도학습의 효과를 낼 수 있다는 내용이다.

논문이 출간된 시점 고성능을 내는 방식의 시스템의 단점과 GPT-2가 바라는 시스템에 대해 서술돼 있다.

지속적으로 현재 시스템의 문제와 저자가 생각하는 문제 원인을 말한다.

NLP의 멀티태스킹 교육은 여전히 초기 단계라고 한다. 현재 ML 시스템은 일반화가 잘 되는 함수를 유도하기 위해 수백에서 수천 개의 예제가 필요가 필요하다고 한다.

본 논문에서 성취하길 원하는 목표를 말한다.

이 그림은 언어 모델의 크기와 다양한 자연어 처리 작업에서의 성능 간의 관계를 나타내고 있다

GPT-2의 접근 방식의 핵심이 언어 모델링이라고 한며 p(x) = ∏ p(si|s1, …, si-1)에 대한 이야기를 한다.

GPT-2는 지도 없이도 task를 학습할 수 있다. McCann은 muti-task learning으로 실제 여러 개의 dataset을 학습한것이라면 GPT-2는 Language Model을 unsupervised-learning으로 했다는 것이다.
# 번역 작업 예시 각각 요소 사이에는 시컨스로 지정하는 기호로 구분해야함
# 작업, 영어 텍스트, 프랑스어 텍스트
("프랑스어로 번역 작업", "I love programming.", "J'adore la programmation.")
# 독해 작업 예시 각각 요소 사이에는 시컨스로 지정하는 기호로 구분해야함
# 작업, 문서 질문, 답변
("질문과 답변", "A는 컴퓨터 공학과 수학을 좋아한다.", "A가 좋아하는 것은?", "컴퓨터공학")

언어 모델링은 기본적으로 문장을 생성하거나 이해하는 작업을 수행하는 것이다. 예를 들어, “I love programming.”이라는 문장을 생성하거나 이해하는 능력을 갖게 된다.
논문에서 언급한 내용은, 이 언어 모델이 “번역 작업”이라는 작업을 수행할 수 있는지를 논의한다. 논문은 언어 모델이 “번역 작업”을 하면서, 어떤 심볼이 실제로 번역 출력값인지를 따로 알려주지 않아도 학습할 수 있는지를 확인한다. 실제로 모델이 이러한 작업을 학습할 수 있다면, 사실상 감독 없이 다양한 작업을 수행하는 능력을 갖게 될 것이다. 이를 평가하기 위해 제로샷 설정으로 다양한 작업을 테스트할 예정이다.

논문의 저자들은 직접 데이터 필터링을 수행하는 대신, 웹 페이지 중에서도 사람들에 의해 고른 내용만 추출하여 데이터셋을 구축했다. 이를 위해 Reddit라는 소셜 미디어 플랫폼에서 적어도 3개 이상의 카르마를 받은 게시물의 링크들을 추출했다. 이런 방식으로 다른 사용자들이 해당 링크를 흥미롭거나 교육적이거나 재미있는 것으로 생각한지를 휴리스틱하게 판단한 것이다. 데이터셋은 약 4500만개의 링크에서 추출한 텍스트로 이루어져 있으며, HTML 응답에서 텍스트를 추출하기 위해 Dragnet과 Newspaper1 컨텐츠 추출기의 조합을 사용했다. 이 데이터셋은 2017년 12월 이후에 생성된 링크를 포함하지 않고 중복 제거 및 일부 휴리스틱 기반 클리닝을 수행하여 총 8백만 개가 넘는 문서, 총 40GB의 텍스트로 구성된다.

현재의 대규모 언어 모델은 소문자 변환, 토큰화, 어휘에 없는 토큰 등의 전처리로 인해 모델이 다룰 수 있는 문자열이 제한된다. 유니코드 문자열을 UTF-8 바이트의 시퀀스로 처리하면 이 문제를 해결할 수 있다. 그러나 현재의 바이트 수준 언어 모델은 큰 데이터셋에서 단어 수준 언어 모델과 경쟁에서 밀리는 경우가 많다.
# 바이트 단위
입력: "banana"
글자로 나눈 결과: "ba", "na", "na"
# 유니코드 포인터 단위
입력: "banana"
유니코드 코드 포인트로 나눈 결과: "b", "a", "n", "a", "n", "a"
# 글자 단위
입력: "hello"
글자로 나눈 결과: "b", "a", "n", "a", "n", "a"
Byte Pair Encoding (BPE)는 글자와 단어 수준 언어 모델 사이의 실용적인 중간 방식으로, 빈번한 기호 열에 대해 단어 수준 입력을, 드물게 등장하는 기호 열에 대해 글자 수준 입력을 효과적으로 보완한다.
#"I love cats." 문장을 UTF-8 바이트 시퀀스로 변환 (예시 입니다! 정상 작동 x)
UTF-8 바이트 시퀀스: [73, 32, 108, 111, 118, 101, 32, 99, 97, 116, 115, 46]
# 인코딩
73: 'I'
32: 공백(space)
108: 'l'
111: 'o'
118: 'v'
101: 'e'
32: 공백(space)
99: 'c'
97: 'a'
116: 't'
115: 's'
46: '.'
#"I love cats." 문장을 UTF-8 바이트 시퀀스로 변환 만일 lo와 ve가 많이 나온다면 (예시 입니다! 정상 작동 x)
UTF-8 바이트 시퀀스: [73, 32, 199, 200, 32, 99, 97, 116, 115, 46]
# 인코딩
73: 'I'
32: 공백(space)
199: 'lo'
200: 've'
32: 공백(space)
99: 'c'
97: 'a'
116: 't'
115: 's'
46: '.'
그러나 바이트 단위의 병합에도 문제가 있다. “cat.”, “cats”, “cat!”의 경우 무의미한 서브워드(Subword)가 다량 많들어 질 수도 있다.
논문에서는 병합을 통해 유의미하지 않은 단어의 버전을 방지하고 Vocabulary의 크기를 효율적으로 관리하려는 목적으로 문자 수준 이상의 병합을 막았다고 언급한다.

논문에서는 Transformer 아키텍처를 기반으로 하는 언어 모델을 사용하며, 이 모델은 OpenAI GPT 모델을 기반으로 하되 몇 가지 수정 했다고 한다.
레이어 정규화란 레이어에서 활성화 함수를 통과하기 전에 입력 데이터를 평균과 분산을 이용하여 조정하는 것이다.
잔차 레이어는 입력 데이터를 처리하여 출력을 생성하는 과정에서 입력과 출력 간의 잔차를 계산하고, 이를 기존의 출력에 더해주는 역할을 한다. (네트워크의 깊이가 증가함에 따른 그래디언트 소실 문제를 완화하고, 더 깊은 네트워크를 학습하는 데 도움을 주는 역할)
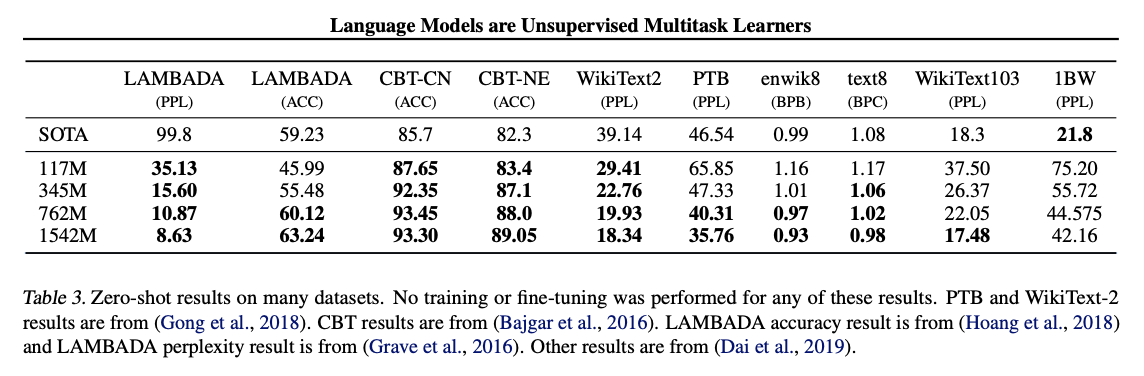

이 실험에서는 근사적으로 로그-균일하게 분포된 크기를 가진 네 개의 언어 모델(LM)을 훈련하고 평가했다.

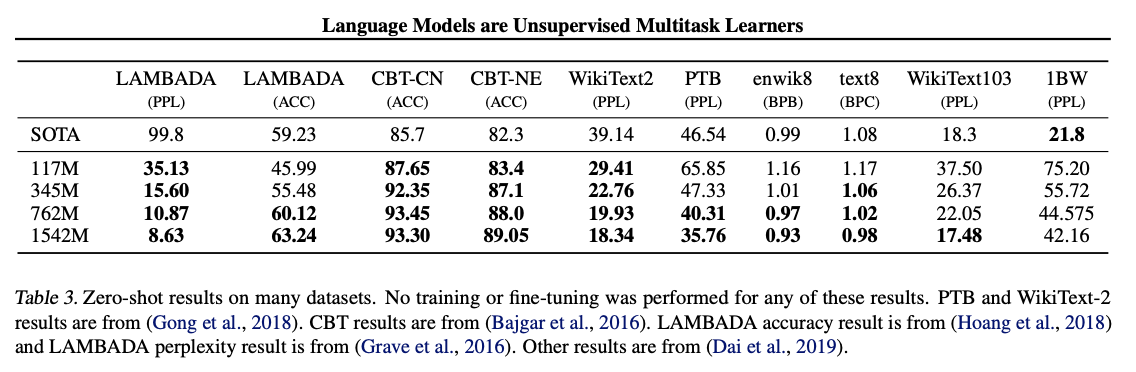
제로샷 도메인 이전에 대한 웹텍스트 언어 모델의 성능을 이해하고자 하는 초기 단계로, 웹텍스트 언어 모델이 훈련된 주요 작업인 언어 모델링에 대한 제로샷 도메인 이전을 어떻게 수행하는지에 관심이 있다. 저희 모델은 바이트 수준에서 작동하며 손실이 있는 전처리나 토큰화를 필요로하지 않기 때문에 어떤 언어 모델 벤치마크에서든 평가할 수 있다.
이러한 디토크나이저를 사용하여 GPT-2의 퍼플렉서티가 2.5에서 5까지 향상되는 것을 관찰합니다.
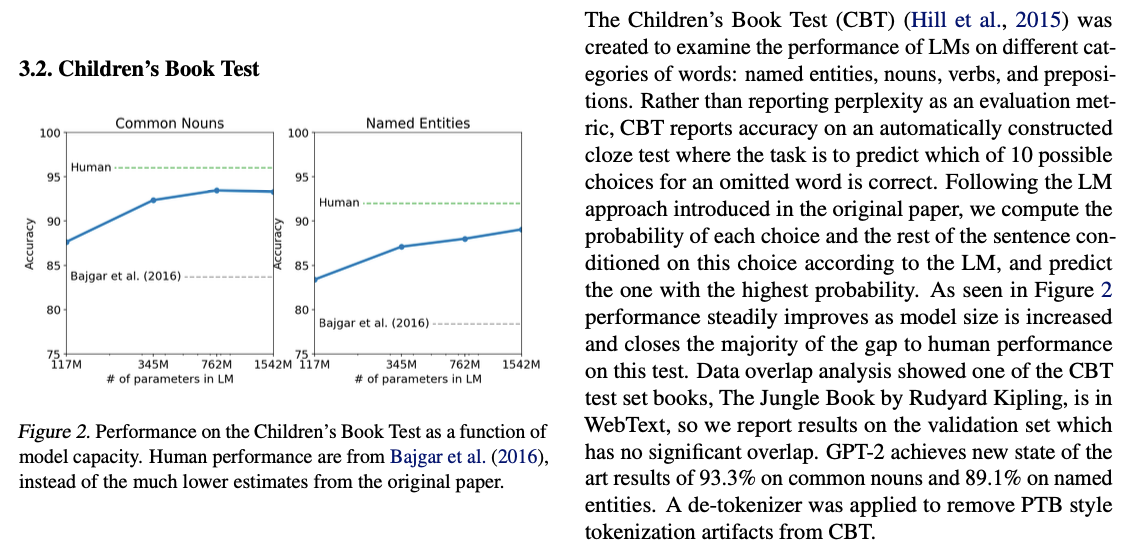

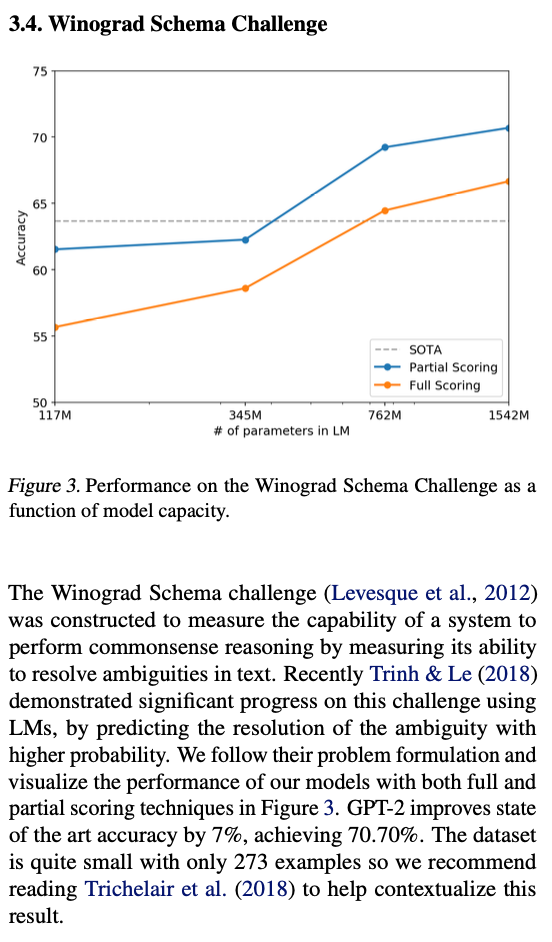





최근의 컴퓨터 비전 연구에서는 일반 이미지 데이터셋에는 중복 이미지가 상당량 포함되어 있음을 보여주었다. 예를 들어, CIFAR-10 데이터셋은 훈련 이미지와 테스트 이미지 간에 3.3%의 중복이 있습니다 (Barz & Denzler, 2019). 이로 인해 기계 학습 시스템의 일반화 성능이 과대 보고되는 결과가 나타난다. 데이터셋의 크기가 증가함에 따라 이 문제는 더욱 발생 가능성이 높아지며, 이것은 WebText에서도 유사한 현상이 발생할 수 있다는 것을 시사한다. 따라서 테스트 데이터가 훈련 데이터에 얼마나 자주 나타나는지를 분석하는 것이 중요하다.

이를 연구하기 위해 WebText 훈련 세트 토큰의 8-gram을 포함하는 블룸 필터를 만들었다. 재현율을 향상시키기 위해 문자열을 소문자 알파벳 및 숫자로만 구성된 단어로 정규화하고 구분자로 하나의 공백만을 포함하도록 했다. 블룸 필터는 거짓 양성률이 상한선으로 제한되도록 생성됐다. 연구진들은 거짓 양성률이 매우 낮음을 추가로 확인하기 위해 100만 개의 문자열을 생성하고, 그 중 어떤 것도 필터에서 찾지 못했다.

웹텍스트 훈련 세트와 다양한 언어 모델(LM) 벤치마크의 테스트 세트 간 중복을 조사하기 위해 블룸 필터를 활용했다. 일반적인 LM 벤치마크의 테스트 세트는 WebText 훈련 세트와 약 1-6%의 중복을 가지며, 자체 훈련 세트와의 중복률이 평균적으로 더 높았다(평균 5.9%). 이 중복은 중복 데이터와 관련이 있으며, 일부 데이터 세트에서는 중복 데이터로 인해 더 긴 일치 사례가 발생했다. 결과적으로 데이터 세트 간 중복은 일반적인 현상이며, 유용한 정보를 얻는 데 도움이 되지 않을 수 있다.

웹텍스트 훈련 데이터와 특정 평가 데이터셋 간의 데이터 중복을 조사했다. 결과적으로 데이터 중복은 보고된 결과에 작은 그러나 일관된 이점을 제공하는 것으로 나타났다. 그러나 대부분의 데이터셋에서 표준 훈련 및 테스트 세트 간 이미 존재하는 중복과 크게 다른 중복을 발견하지 못했다. 이러한 중복이 모델 성능에 어떻게 영향을 미치는지 이해하고 양적으로 파악하는 것은 중요한 연구 질문이다. 나중에 더 나은 중복 제거 기술을 사용하여 이러한 질문에 더 나은 답을 찾을 수 있을 것으로 생각된다. 현재로서는 n-그램 중복을 기반으로 한 중복 제거를 중요한 확인 단계 및 새로운 NLP 데이터셋의 훈련 및 테스트 분할 생성 중 실질적으로 쓸모 있는 검증 단계 및 정상성 확인으로 권장한다.
또한 WebText LMs의 성능이 기억력에 기인하는지 여부를 결정하는 또 다른 방법은 자체 보류 세트에서의 성능을 검사하는 것이다. 그림 4에서 볼 수 있듯이, WebText의 훈련 및 테스트 세트에서의 성능은 유사하며 모델 크기가 증가함에 따라 함께 향상된다. 이는 GPT-2조차도 여전히 WebText에서 여러 측면에서 과소적합 상태임을 시사한다.
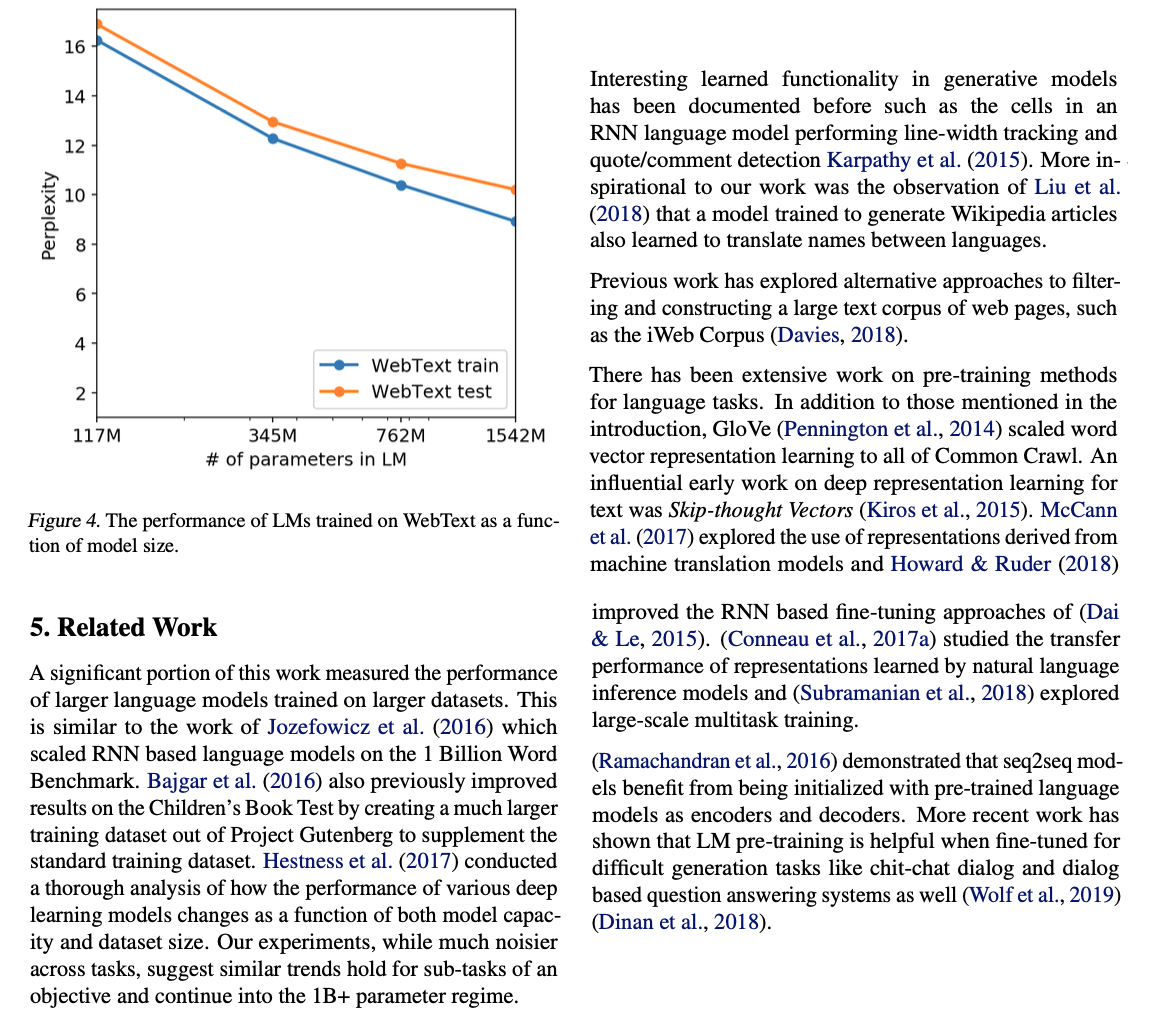
이 작업의 중요한 부분은 더 큰 언어 모델이 더 큰 데이터셋에서 훈련된 결과를 측정한 것이다. 이는 Jozefowicz 등의 연구 (2016)와 유사한데, 이 연구에서는 RNN 기반 언어 모델을 10억 개 단어 벤치마크에 맞게 확장했다. Bajgar 등 (2016)도 기존 훈련 데이터셋을 보완하기 위해 Project Gutenberg에서 훨씬 큰 교육 데이터셋을 만들어 아동 도서 테스트의 결과를 개선했다. Hestness 등 (2017)은 모델 용량 및 데이터셋 크기의 함수로서 다양한 딥 러닝 모델의 성능이 어떻게 변하는지에 대한 철저한 분석을 수행했다. 우리의 실험은 작업별로 훨씬 더 많은 잡음이 있지만 목적의 하위 작업 및 10억 개 이상의 매개변수 범주에 대한 유사한 추세가 유지됨을 시사한다.
생성 모델에서 발견된 흥미로운 학습 기능은 이전에 문서 너비 추적 및 인용/코멘트 감지와 같은 RNN 언어 모델의 셀에서 수행된 것과 같이 문서 너비 추적 및 인용/코멘트 감지를 수행하는 것 등과 같은 것이 문서로 남아 있다. Karpathy 등 (2015)의 이러한 작업은 우리의 작업에 영감을 주었다. 또한, Liu 등 (2018)이 보고한 바와 같이 Wikipedia 기사를 생성하도록 훈련된 모델이 언어 간 이름 번역을 학습하는 것과 같이 더 활기찬 작업이 이루어진 것도 주요한 영향을 끼쳤다.
이전 연구에서는 웹 페이지의 대규모 텍스트 코퍼스를 필터링하고 구성하는 대안적인 접근 방식을 탐구한 바 있으며, 이 예로는 iWeb Corpus (Davies, 2018)가 있다.
언어 작업의 사전 훈련 방법에 대한 광범위한 연구가 수행됐다. 소개에서 언급된 연구들 외에도 GloVe (Pennington 등, 2014)는 모든 Common Crawl에 대한 단어 벡터 표현 학습을 확장했다. 텍스트에 대한 깊은 표현 학습에 대한 영향력 있는 초기 연구는 Skip-thought Vectors (Kiros 등, 2015)였습니다. McCann 등 (2017)은 기계 번역 모델에서 유도된 표현을 사용하는 방법을 탐구했으며, Howard & Ruder (2018)는 (Dai & Le, 2015)의 RNN 기반 미세 조정 접근 방식을 개선했다. (Conneau 등, 2017a)은 자연어 추론 모델에 의해 학습된 표현의 전이 성능을 연구하였으며, (Subramanian 등, 2018)은 대규모 다중 작업 훈련을 탐구했다.
(Ramachandran 등, 2016)은 seq2seq 모델이 사전 훈련된 언어 모델로 초기화될 때 이점을 얻을 수 있음을 보여주었다. 더 최근의 연구는 어려운 생성 작업에 대한 사전 훈련이 도움이 된다는 것을 보여주었으며, 이러한 작업에는 대화식 대화 및 대화 기반 질문 응답 시스템이 포함된다 (Wolf 등, 2019) (Dinan 등, 2018).

많은 연구가 감독 및 비감독 사전 훈련 방법의 표현에 투여되었으며 이를 학습 (Hill et al., 2016), 이해 (Levy & Goldberg, 2014) 및 비평 (Wieting & Kiela, 2019)하는 데 집중하였다. 우리의 결과는 비감독 작업 학습이 탐구할 가치 있는 또 다른 분야임을 시사한다. 이러한 결과는 NLP 작업에서 사전 훈련 기술의 널리 퍼져있는 성공을 설명하는 데 도움이 될 수 있으며, 한 가지 이러한 사전 훈련 기술이 감독적 적응 또는 수정 없이 직접 작업을 수행하기 시작하는 한계를 보여준다.
읽기 이해력에서 GPT-2의 성능은 제로샷 설정에서 감독 베이스라인과 경쟁력이 있다. 그러나 요약과 같은 다른 작업에서는 질적으로 작업을 수행하고 있지만 양적 지표에 따르면 성능은 여전히 기초적이다. 연구 결과로는 유용하지만 실제 응용 분야에서 GPT-2의 제로샷 성능은 여전히 사용 가능한 수준에서는 거리가 멀다.
우리는 WebText LMs의 제로샷 성능을 많은 NLP 고전적 작업에서 연구했지만, 추가로 평가할 수 있는 많은 작업이 있을 것이다. 의심할 여지 없이 GPT-2의 성능이 여전히 무작위보다 낫지 않은 많은 실용적 작업들이 있을 것이다. 우리가 평가한 공통 작업과 같이, 질문 응답 및 번역과 같은 작업에서도 언어 모델은 충분한 용량을 가질 때에만 무의미한 기준선을 뛰어넘기 시작한다.
제로샷 성능은 GPT-2의 많은 작업의 잠재적 성능 기준을 설정하지만, 어디까지 미세 조정을 통해 이루어질 수 있는지는 명확하지 않다. 일부 작업에서 GPT-2의 완전히 추상적인 출력은 현재 많은 질문 응답 및 읽기 이해력 데이터셋에서 최고의 상태인 추출형 포인터 네트워크 (Vinyals et al., 2015) 기반 출력과 유의미한 차이를 보인다. GPT를 미세 조정하는 이전 성공을 고려할 때, 우리는 특히 추가적인 훈련 데이터 및 용량이 GPT-2의 효율성을 극복하기에 충분한지 여부가 불분명한 BERT (Devlin et al., 2018)에 의해 시연된 단방향 표현의 비효율성을 조사할 계획이다.

결론적으로, 충분히 크고 다양한 데이터셋에서 대규모 언어 모델을 훈련시키면 여러 도메인과 데이터셋에서 잘 수행할 수 있다.
이젠 지도 학습 없이 제로샷에서 성능이 나오기 시작한 gpt2이다. 하지만 아직은 파인튜닝을 해야 사용할만한 성능이 나온다. gpt3로 넘어가면서 모델도 공개 안될 뿐더라 파라미터 자체가 너무커 개인이 활용하기 어려운 모델이 됐다… 그래서 아직은 gpt2가 개인 프로젝트에서는 귀한것 같다.
댓글