Language Models are Few-Shot Learners

Review
본 포스트는 함께 GPT를 학습한 정하연님의 도움을 받아 작성된 글 입니다.
더 자세한 gpt3 논문리뷰는 추후 업로드 될 정하연님 블로그에서 보실 수 있습니다.
Abstract

- NLP 모델이 발전하면서 파인-튜닝을 통해 다양한 task를 수행하는 모델을 만들 수 있게 되었다.
- 하지만, 인간은 단 몇 장의 사진(훈련 데이터)으로도 생애 처음 본 사물(테스트 데이터)를 구분할 수 있다. (few-shot learning의 개념)
- GPT-3는 ‘파인-튜닝’ 과정을 제거 하여 few-shot(FS) learning을 통해 몇 개의 샘플만으로도 좋은 성능을 낼 수 있다.
- 매우 큰 데이터셋을 학습시켰기 때문에 파인-튜닝을 하지 않아도 few-shot learning으로 다양한 sub-task들을 수행한다.
- 데이터셋은 3000억개의 데이터셋으로 1750억개의 파라미터를 활용하여 학습했다 (GPT-2는 15억개. GPT-3의 파라미터가 100배 이상 거대함)
- 데이터셋은 단어 뭉치를 의미한다. 3000억개의 데이터셋은 3000억개의 단어를 학습했음을 의미한다.
파라미터(매개변수)
- 서로 다른 함수에 공통적으로 영향을 미치는 변수
- 딥러닝에서 더 나은 결과를 도출하기 위해 1750억개의 가중치(W) & bias(b)를 대입했다는 뜻이다.
Language Model
- 주어진 단어들을 통해 다음 단어를 추측하는 모델
- ex) How are → you?
Autoregressive Language Model
- 과거의 출력값을 현재의 출력값 계산에 사용하는 Language Model
- RNN, Transformer decoder
- ex) How —(GPT)→ are, How are —(GPT)→ you?
Zero-shot Learning (0S)
- 훈련 데이터가 아예 없어도 유연한 패턴인식을 할 수 있다.
- 어떤 문제에 대한 힌트들이 있을 때 딥러닝은 모든 데이터를 분석하는 반면, 제로샷 러닝은 공통점을 이용해 정답을 찾아낸다.
One-shot Learning (1S)
Introduction
- NLP의 발전으로 reading comprehension, Q&A, textual entailment 등의 테스크에서 높은 성능을 보이고 있다.
- 그러나, 이러한 방법의 한계는 task-agnostic(테스크에 구애받지 않는)한 구조에도 불구하고 여전히 task-specific(테스크 명시적인)한 데이터셋과 파인-튜닝을 필요로 한다.
- 논문에서는 3가지 이유를 들어 이러한 한계점을 없애는 것이 바람직하다고 서술한다. 자세한 내용은 생략.
- 이러한 문제를 다루는 한 가지 가능성은 Meta-learning이다.
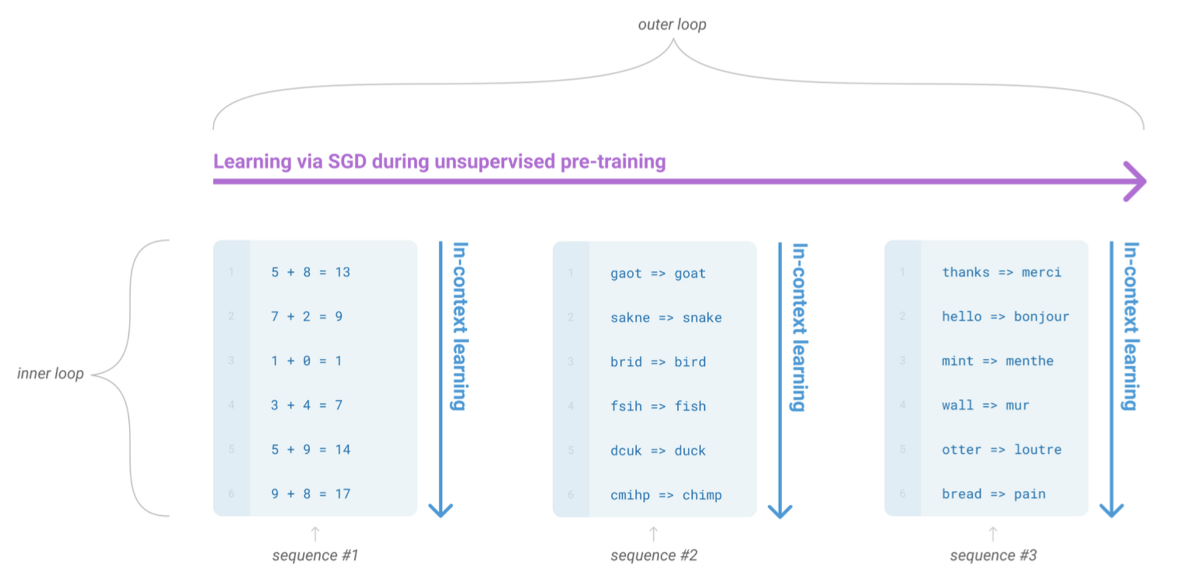
- Meta-Learning: 모델 학습 과정에서, 다양한 스킬과 패턴을 인지하도록 개발하는 것을 의미
- 학습 시에 2개의 루프가 존재한다
- Outer Loop: 비지도 사전학습에서의 SGD를 통한 학습
- Inner Loop: In-context learning (문맥 학습)
- 동일한 테스크 조합들이 하나의 sequence로 들어온다
- 각각의 sequence가 어떤 테스크의 묶음인지 알려주지 않아도, 다양한 테스크들을 하나의 모델이 학습할 수 있도록 유도한다.
- 그러나, Meta-learning은 여전히 파인-튜닝 보다 낮은 성능을 낸다.
논문의 실험 조건
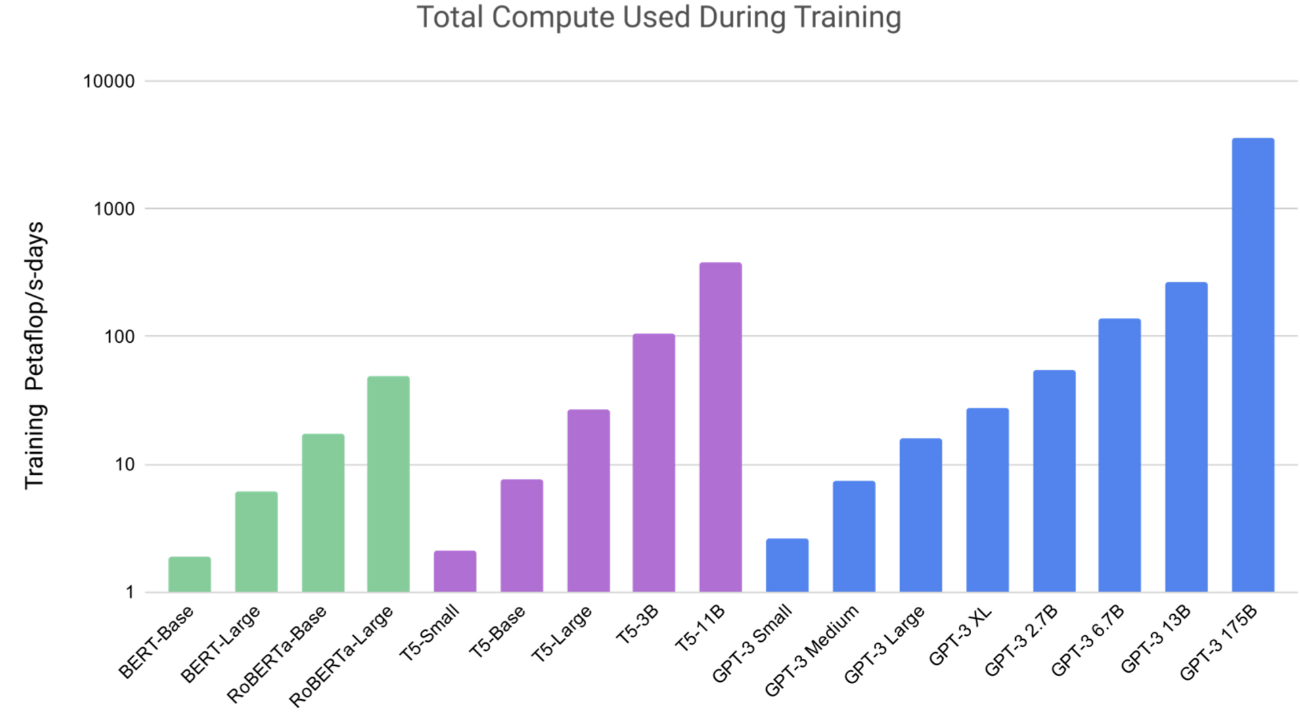
- 선행 연구들은 파라미터 수를 늘리면 NLP 테스크에 발전이 있음을 보여왔다.
- 그래서, 이 논문에서는 1750억개의 파라미터를 사용하여 Auto-regressive Language Model을 훈련시키고, in-context learning 능력을 확인한다.
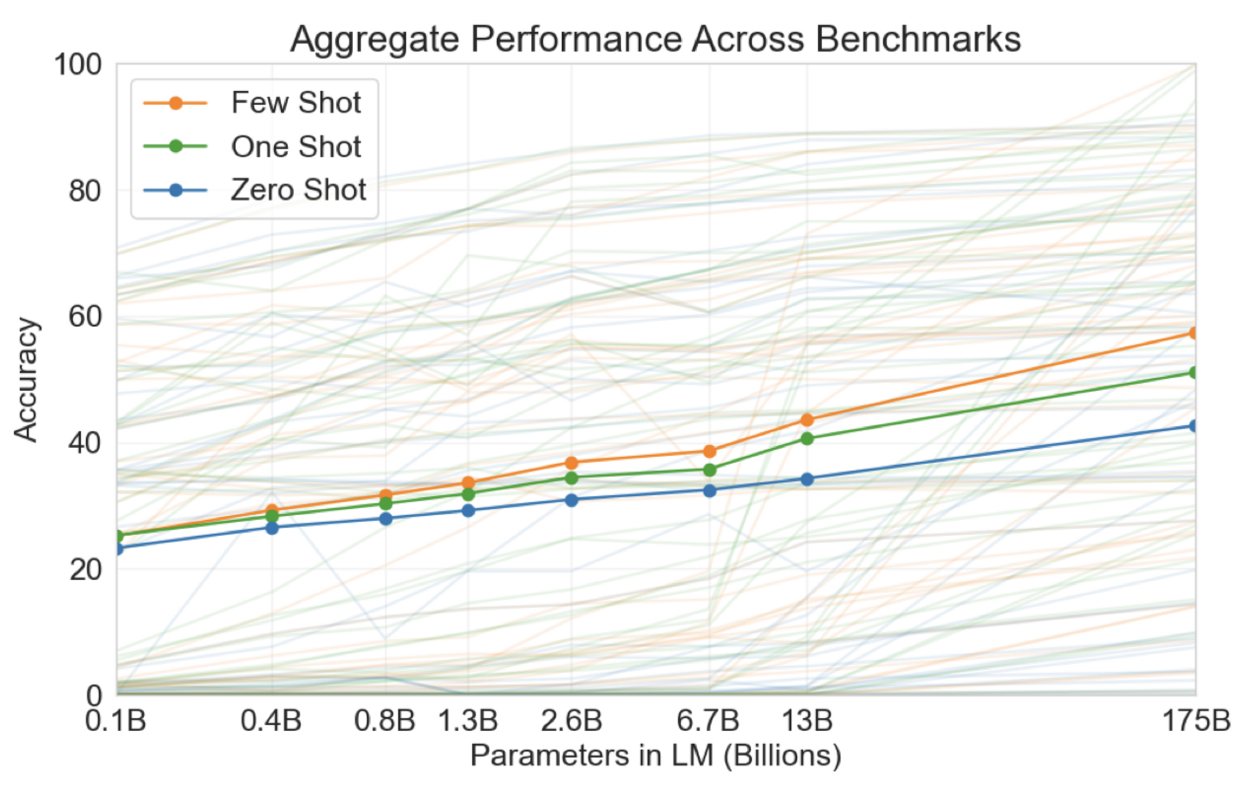
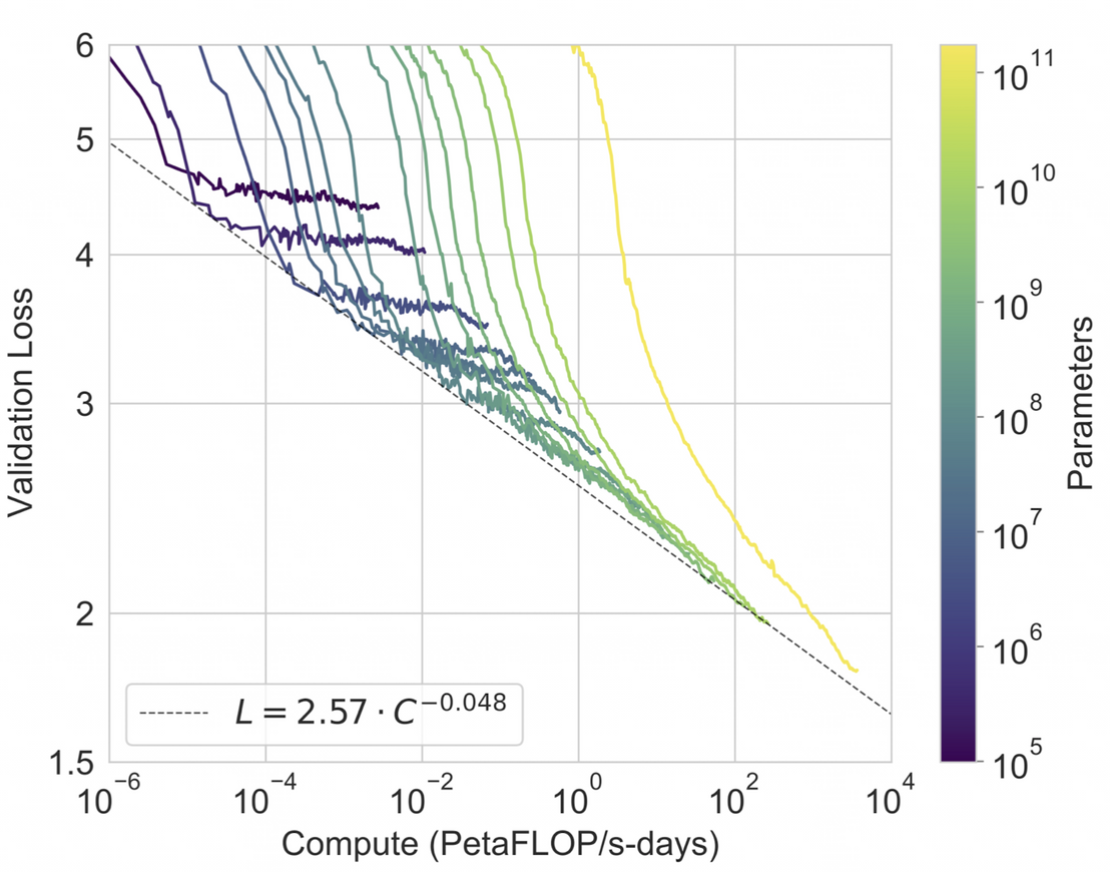
GPT-3의 다양한 테스트에 대한 정확도 종합 그래프
Approach
기존의 fine-tuning 방식

- 첫번째 예시로부터 나온 결과를 보고 gradient update를 한다.
- 두번째 예시로부터 나온 결과를 보고 gradient update를 한다.
- 이 과정이 반복된다.
in-context learning에 대해 3가지를 평가
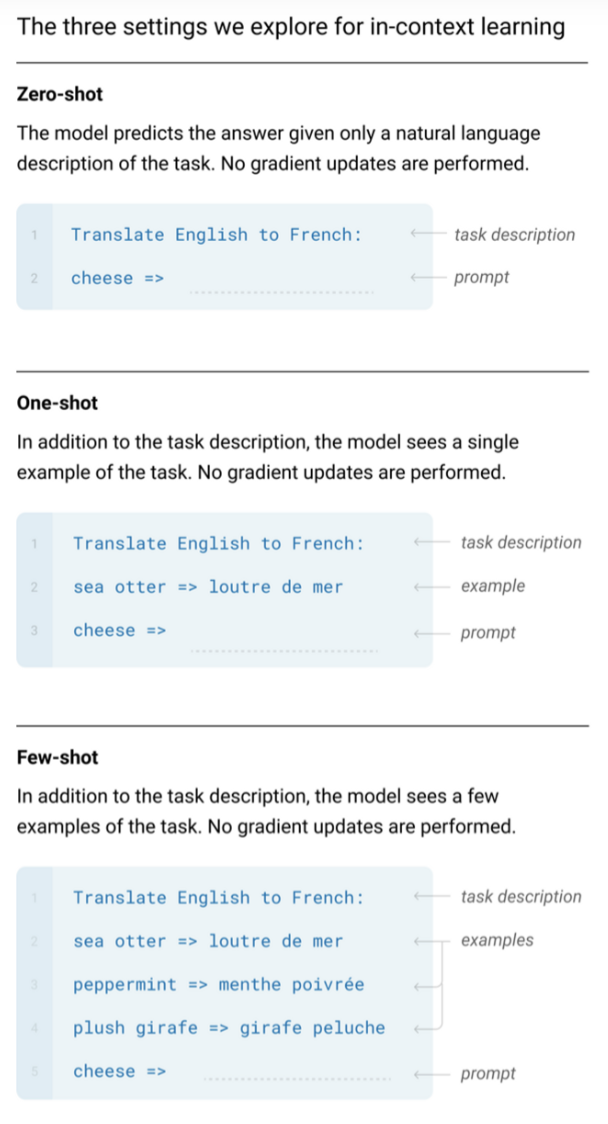
- Translate English to French: cheese ⇒ (총 6개의 토큰/ 이 6개가 한 번에 GPT-3에 입력으로 들어감.)
- one-shot에서는 task description, example, prompt이 하나의 입력으로 들어옴.
- few-shot도 파란 박스 안에 있는 내용이 한 번에 입력됨.
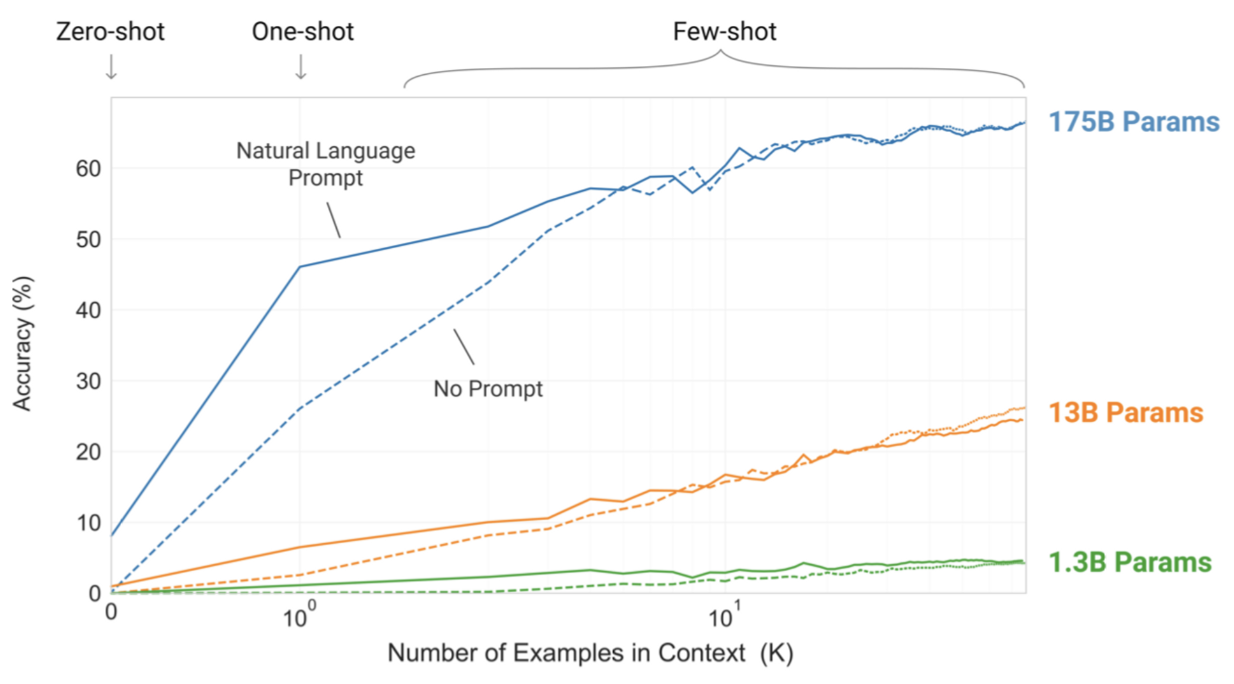
- 이렇게 example들을 늘려갈 수록 성능이 얼마나 발전하는지 Figure 1.3에서 볼 수 있었음.
Model and Architectures

- GPT-3은 GPT-2의 후속버전이라 아키텍처 자체가 크게 달라진 건 없다.
GPT-2와 다른 점: Sparse Attention
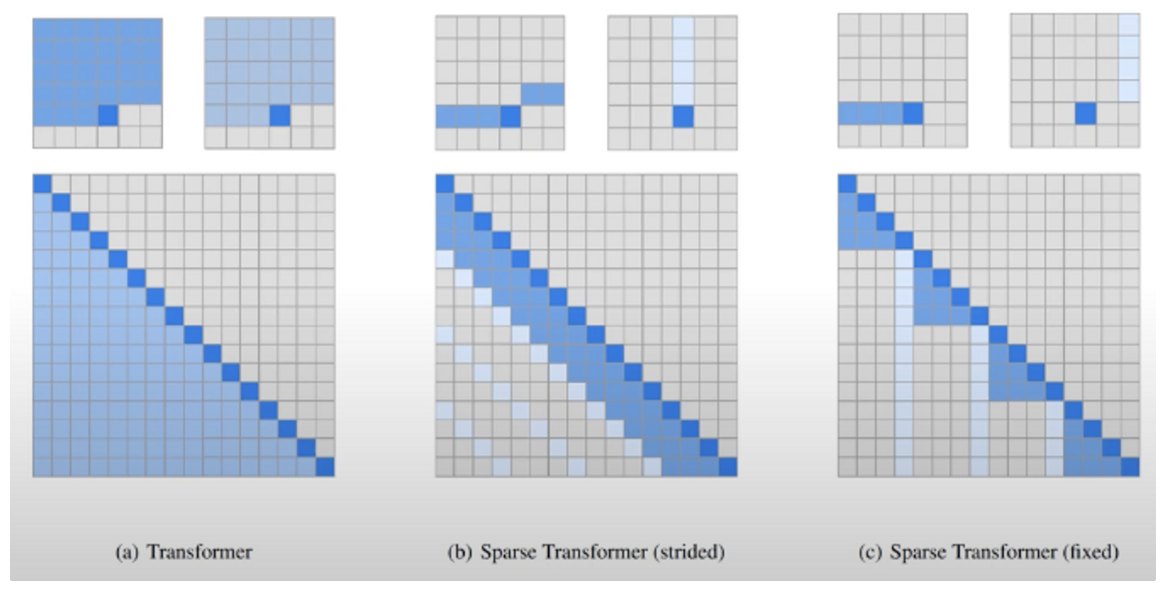
- Strided 방식, Fixed 방식이 있다.
- 자세한 내용은 해당 논문 참고: Child, R, Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
- Decoder 기반의 GPT 구조를 그대로 차용하되, 크기만 키운 것.
- 1750억개의 파라미터, 96개의 디코더, d_model의 차원은 12288,
- d_model: 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기
- n_heads: self-attention에서 사용하는 head의 개수
- GPT-3에서의 토큰의 개수는 모두 동일하게 2^11 = 2048개.
- 입력으로 들어오는 정보는 똑같은데, 그걸 처리하는 모델 사이즈가 8개가 존재하는 것. 그 중 가장 큰게 GPT-3.
Training Dataset
- Common Crawl 데이터셋 (거의 1조 개의 단어)
- 데이터셋의 퀄리티 향상을 위해 3단계의 전처리를 거쳐 사용함.
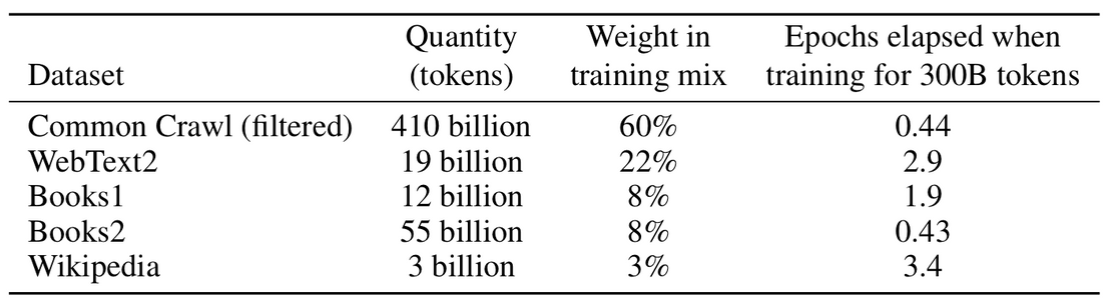
- 위 표에서 Common Crawl의 epoch가 1이 되지 않는다. 모델이 워낙 커서 전체 데이터를 모두 사용하지 않음.
Training Process
…
Evaluation
…
Results
Language Modeling, Cloze, and Completion Tasks
- acc? ppl?
### 1. Acc (Accuracy)
- “Acc”는 “Accuracy”의 약자로, 분류 작업에서 모델의 정확도를 측정하는 지표이다.
- 정확도 = (정확히 분류된 샘플 수) / (전체 샘플 수)
- 값이 높을수록 모델이 더 좋은 성능을 나타냅니다.
### 2. ppl (Perplexity)
- “Ppl”은 “Perplexity”의 줄임말로, 언어 모델링에서 사용되는 평가 지표이다.
- 모델이 주어진 문장을 얼마나 잘 예측하는지를 나타낸다.
- 낮은 Ppl 값은 모델이 입력 문장의 다음 단어를 더 잘 예측한다는 것을 의미한다.
- ppl = exp(크로스 엔트로피 손실)
- 여기서 크로스 엔트로피 손실은 모델의 예측 분포와 실제 분포 간의 차이를 나타내며, exp는 자연로그의 역함수인 지수 함수를 의미한다. Ppl 값이 낮을수록 모델의 예측이 더 좋다고 판단된다.
Language Modeling

- Penn Tree Bank(PTB) 데이터에 대해 기존 zero-shot SOTA보다 성능이 좋았음.
- PTB: 미국 펜실베니아 대학교(Pennsylvania University)에서 구축한 영어 언어 모델링 데이터셋.
- 언어 모델링은 주어진 단어나 문장의 일부를 바탕으로 다음 단어를 예측하는 작업으로, 문장 생성, 기계 번역, 자동 요약 등을 한다.
- PTB 데이터셋은 이러한 작업에 사용되는 모델을 평가하고 비교하는 데 활용된다.
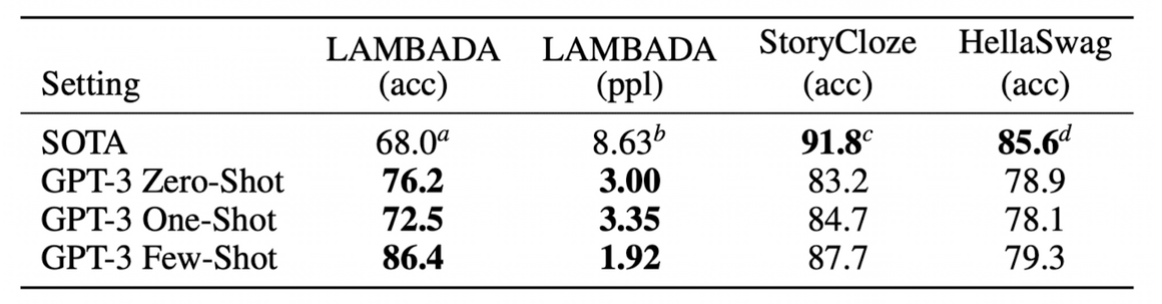
LAMBADA
- 문장의 마지막 단어를 예측하는 작업이며, 단순한 문장 완성보다 더 높은 문맥 이해를 요구한다. 이 데이터셋은 대부분 소설과 이야기에서 추출된 문장으로 구성되며, 문장의 내용과 맥락을 이해한 후 마지막 단어를 정확하게 예측해야 한다.
- 장기적인 의존성과 문맥에 민감한 작업에 대한 모델의 성능을 평가하는 데 유용하다.
-
예시

- 모델 크기에 따른 LAMBADA의 정확도 (zero-, one-, few-shot)
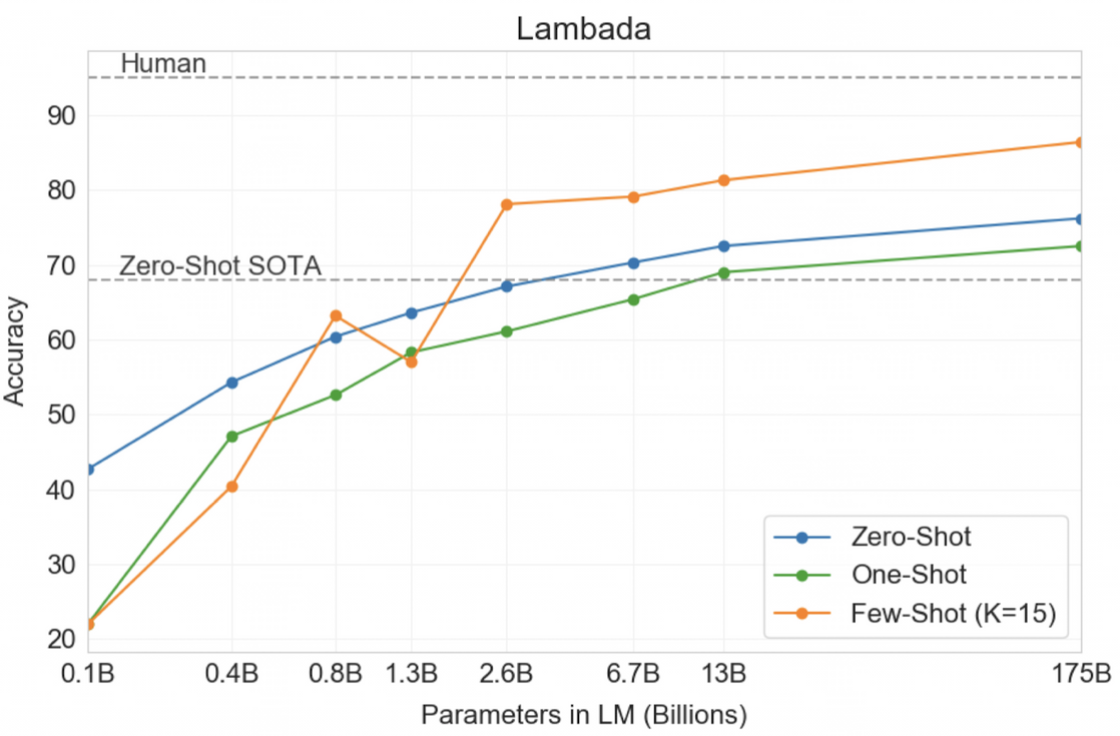
HellaSwag
- 짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 테스크.
- 모델은 어려워하지만 사람에게는 쉽다.
- 현재 fine-tuning한 SOTA 모델을 뛰어넘지는 못했다.
Storycloze
- 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 테스크.
- few-shot: BERT 기반의 fine-tuning한 SOTA 모델을 뛰어넘진 못했다.
- 하지만, 기존 zero-shot의 성능은 10% 가까이 뛰어넘었다.
Closed Book Question Answering
- 폭넓은 사실 기반의 지식에 대한 질문에 답할 수 있는지 측정한다.
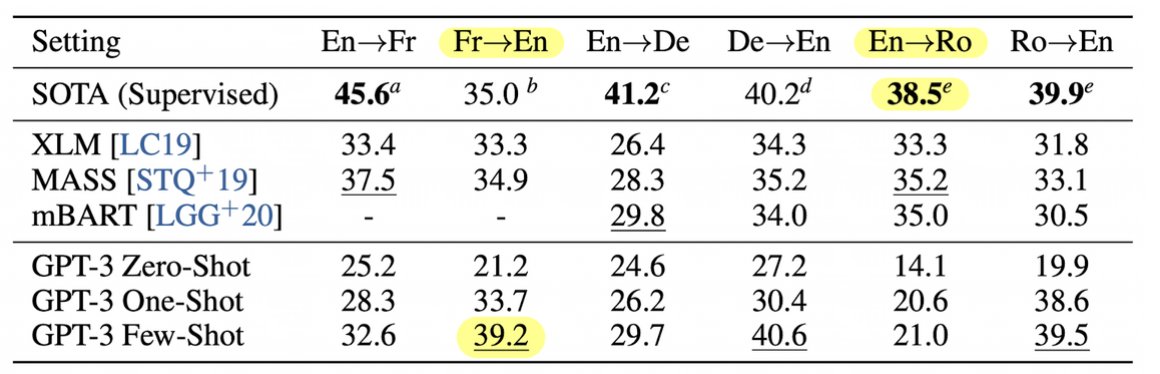
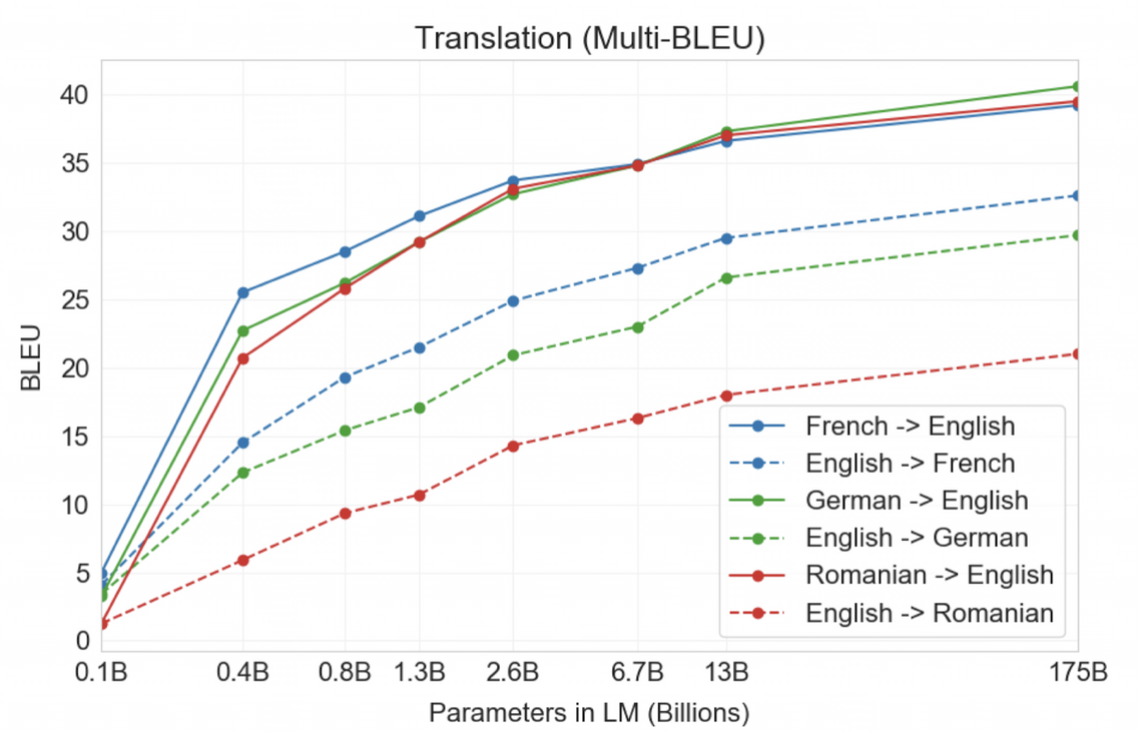
Translation
- 사전학습에 사용한 데이터의 93%는 영어, 7%는 다른 언어르 포함했다.
- 불어-> 영어 / 독어-> 영어에 대해서는 supervised 세팅의 SOTA보다 좋은 성능을 얻기도 했다.
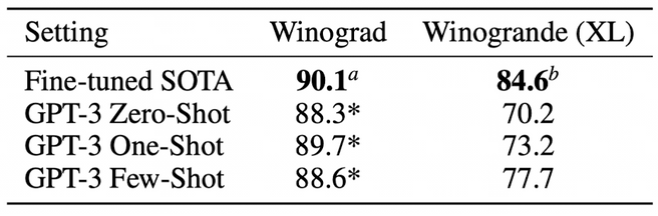
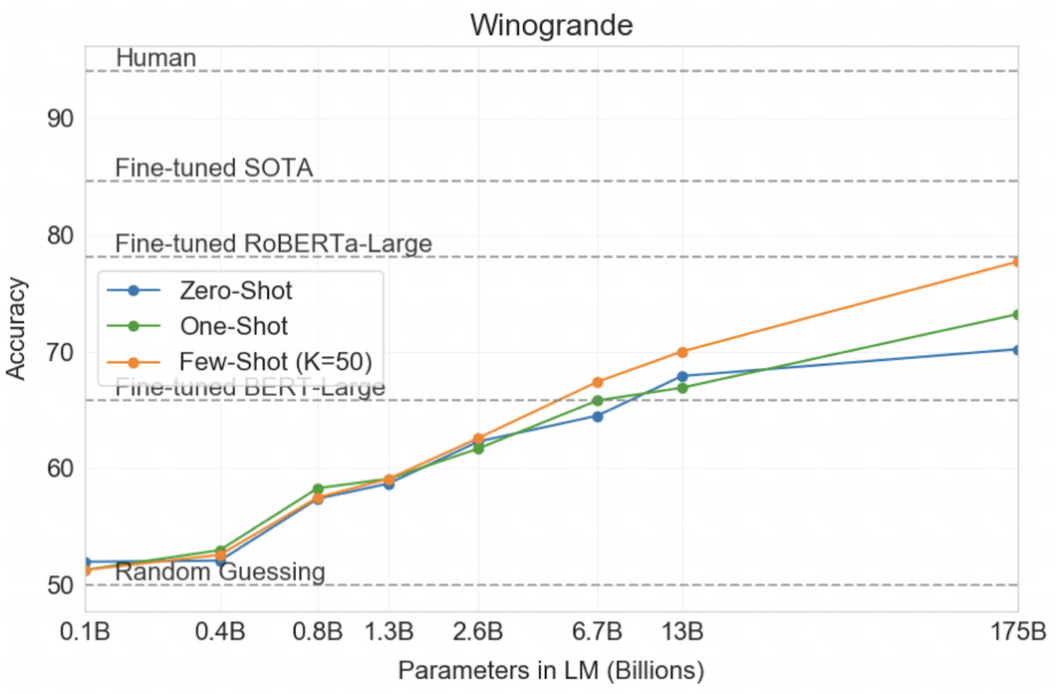
Winograd-Style Tasks
- 대명사 지칭 문제
- 모델의 파라미터가 많을수록 성능이 좋아지지만, fine-tuned SOTA의 성능을 능가하진 못함.
Common Sense Reasoning
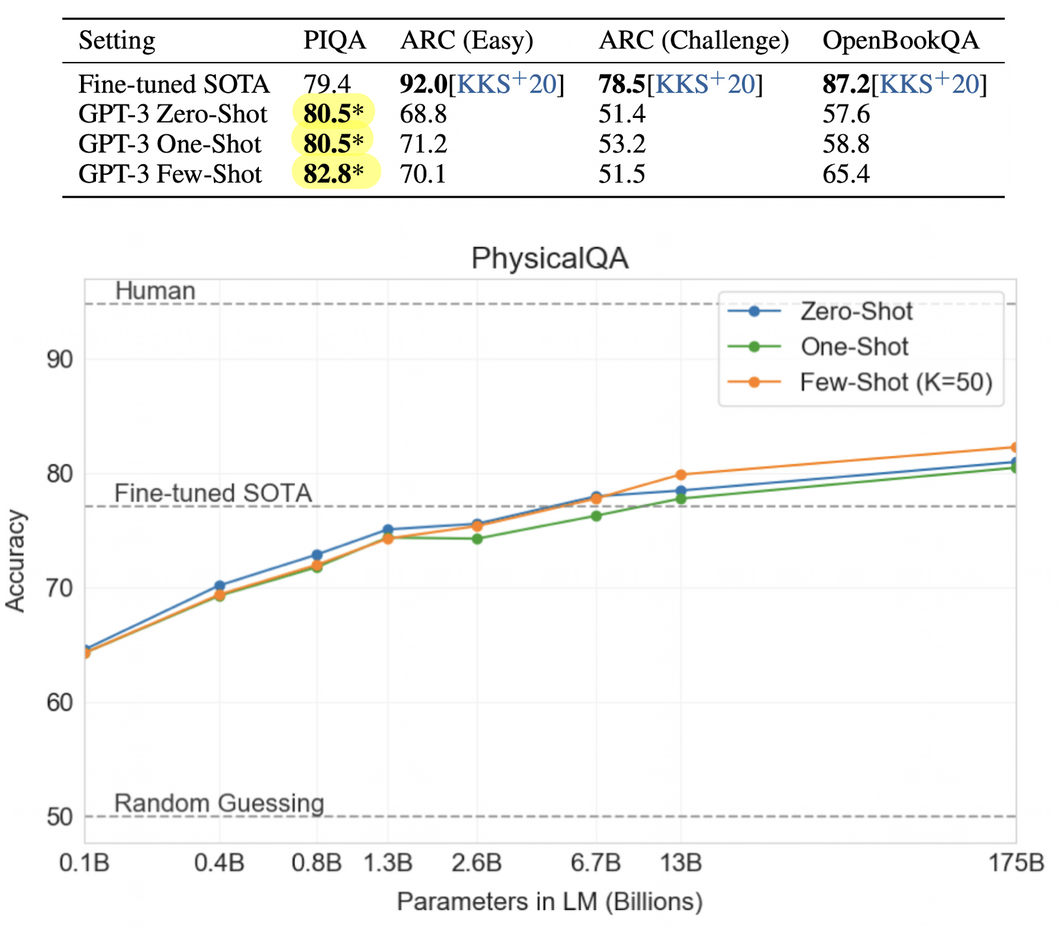
- PIQA(Physical Q&A): 물리학이 어떻게 작동하는지 묻는 실험
- ARC: 3~9학년 과학 시험 수준의 4지선다형 문제
- OpenBookQA: few-shot이 zero-shot setting 대비 크게 성능 향상이 있어 in-context learning을 해낸 것으로 보이나, 역시 SOTA에는 미치지 못하는 성적이었다.
Reading Comprehension
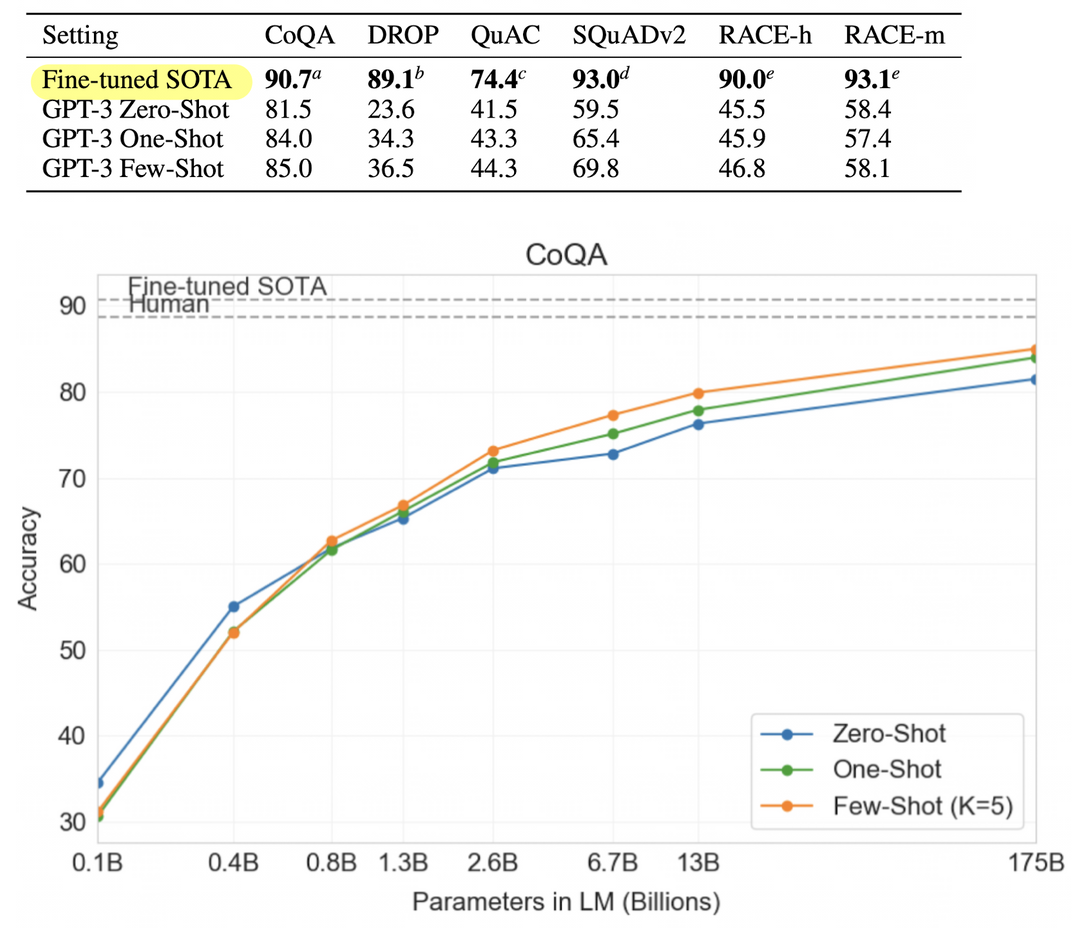
SuperGLUE
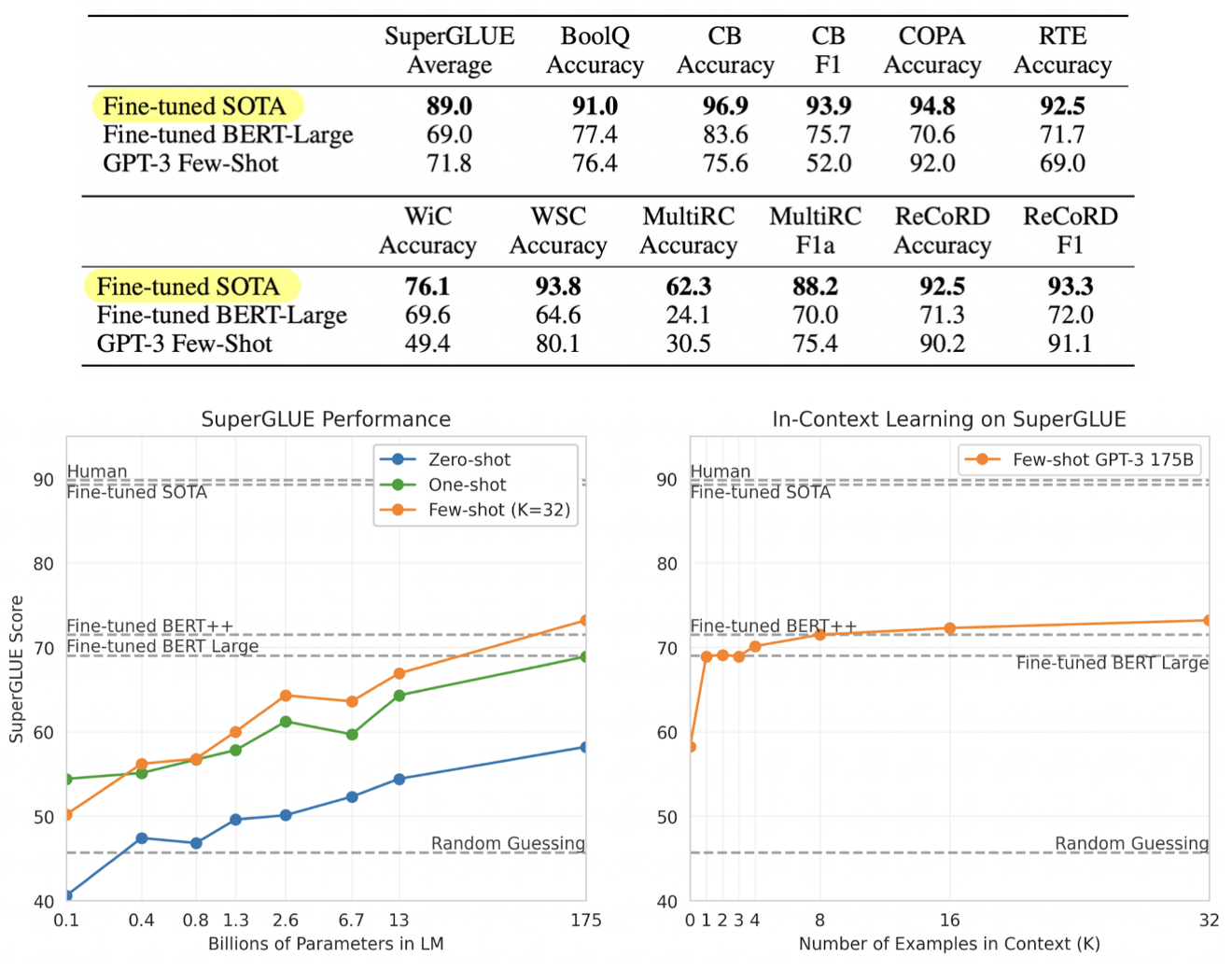
NLI
- Natural Language Inference (NLI)
- 두 문장 간의 관계를 추론
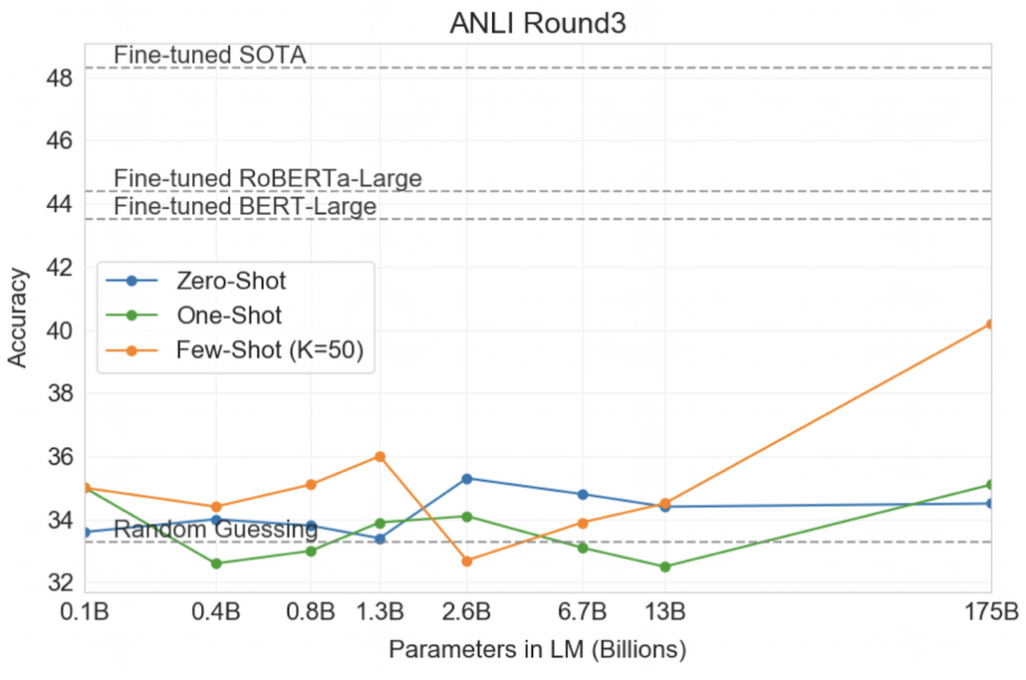
Synthetic and Qualitative Tasks
Arithmetic
- 2~5 자릿수 덧셈/ 뺄셈 , 두 자릿수 곱셈, 한 자릿수 복합 연산 태스크를 GPT-3가 풀 수 있을지 테스트
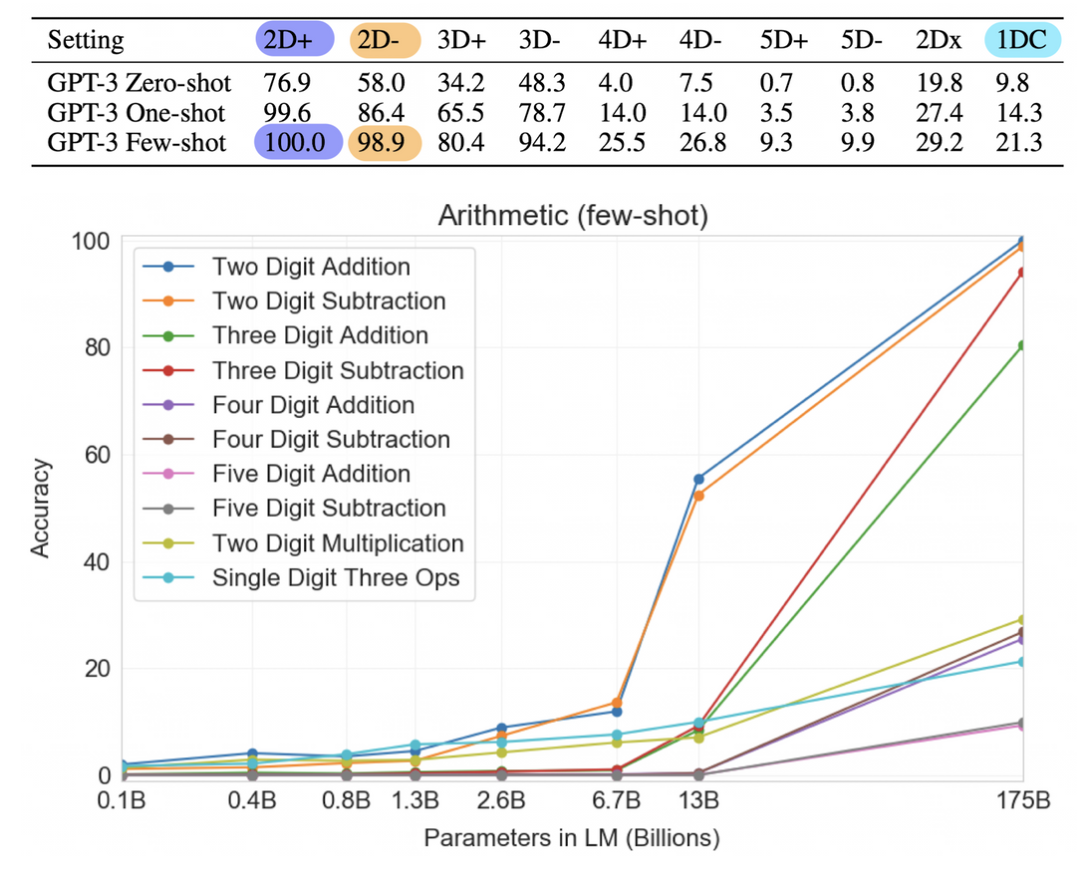
- 2자리 덧셈/뺄셈은 175B 모델은 거의 완벽하다.
- 4자릿수 이상의 계산부터 성능이 매우 떨어졌고, 하나 이상의 계산을 넘어가면 강건성이 떨어진다.
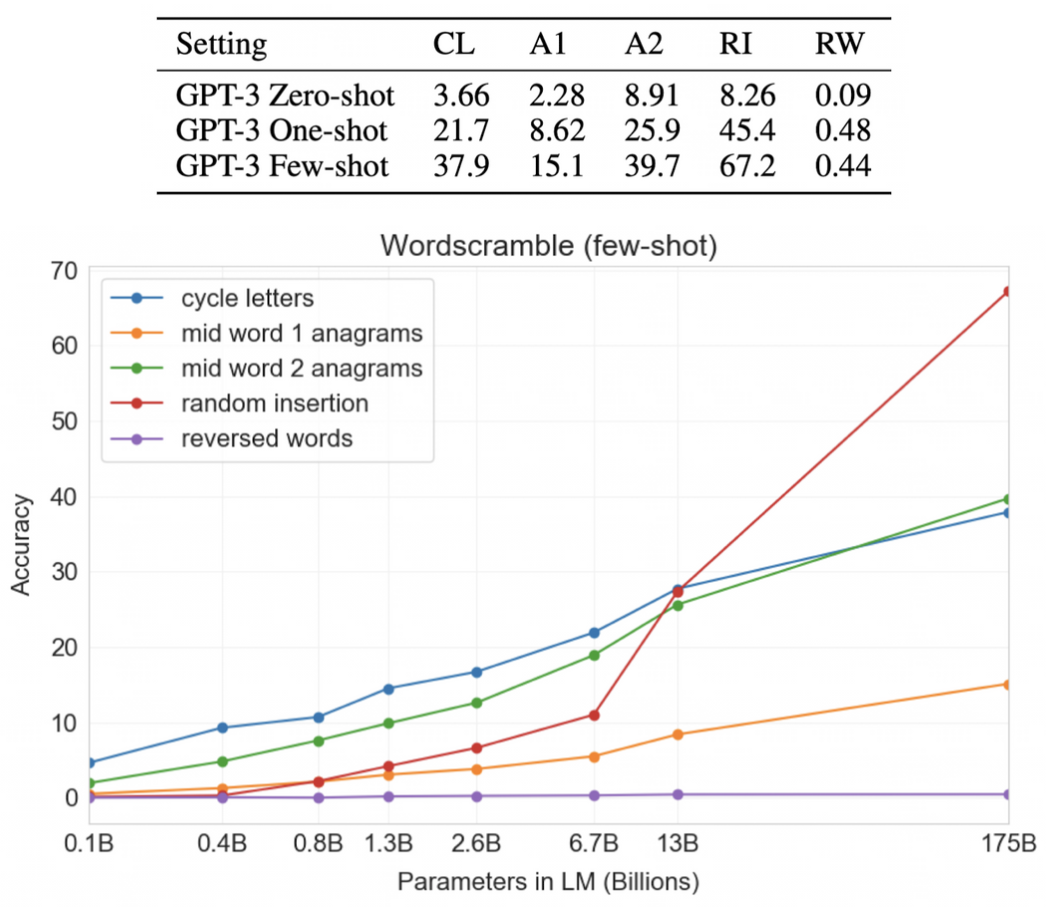
Word Scrambling and Manipulation Tasks
- Cycle letters in word (CL)
- Anagrams of all but first and last characters (A1)
- Anagrams of all but first and last 2 characters (A2)
- Random insertion in word (RI)
- Reversed words (RW)
- elppa → apple
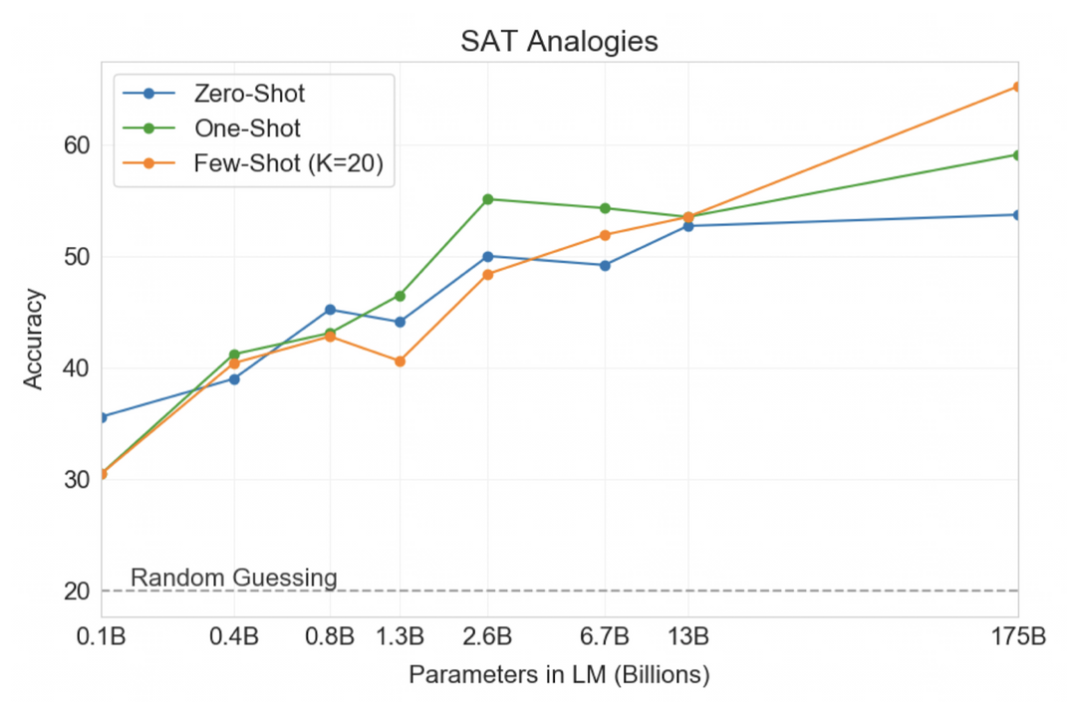
SAT Analogies
- SAT 5지선다 문제 풀기
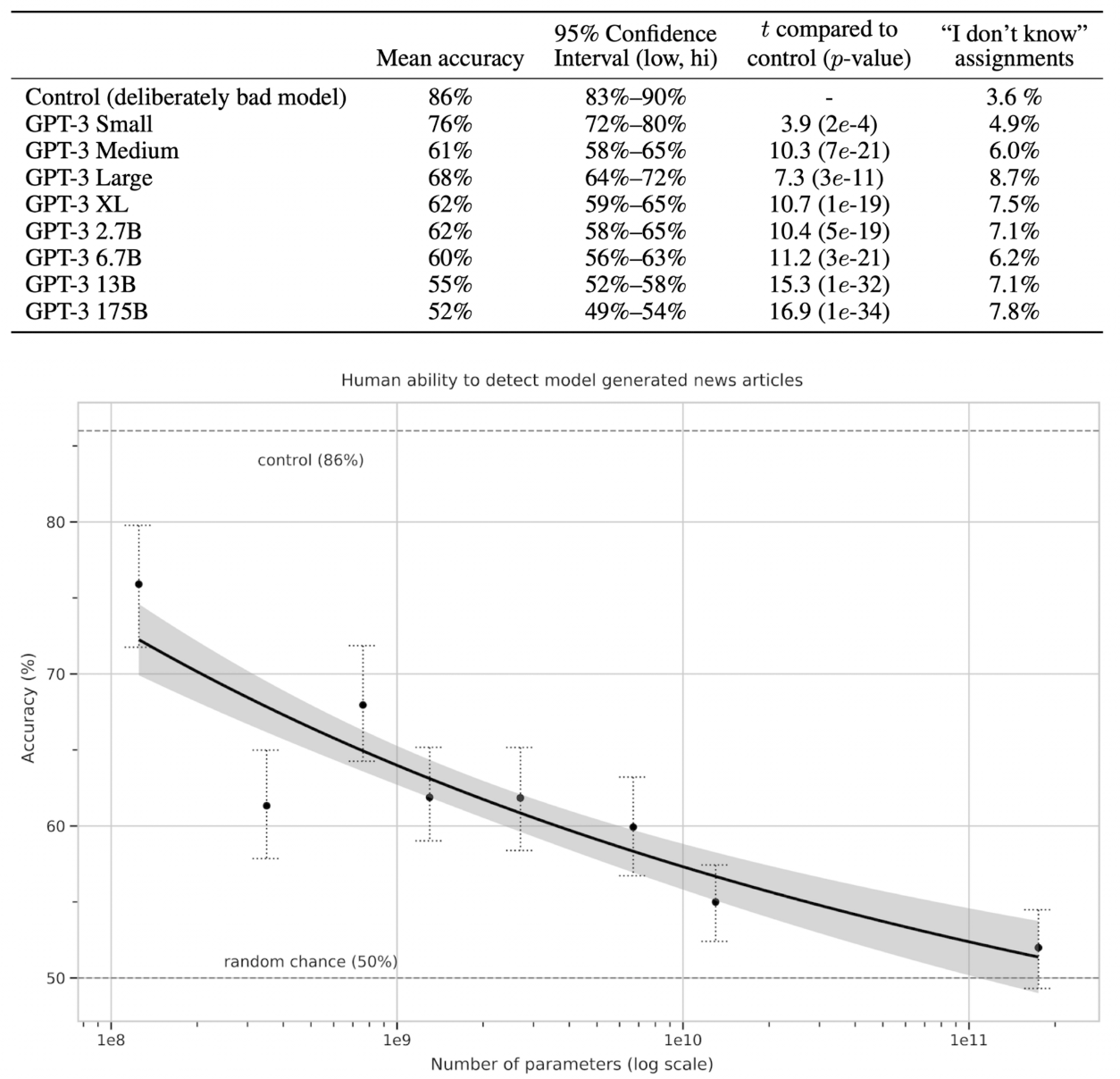
News Article Generation
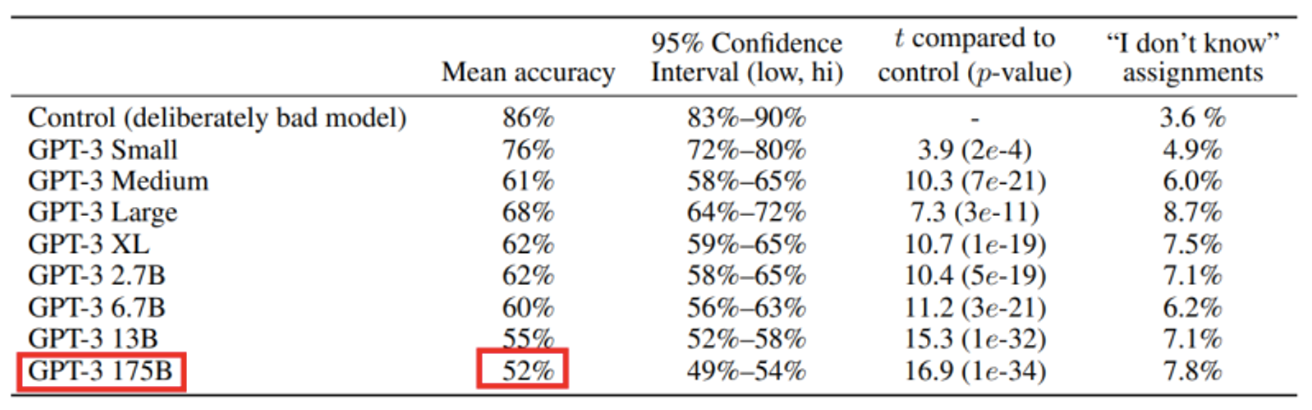
- 200단어 미만의 짧은 뉴스가 사람이 쓴 건지 모델이 생성한건지 사람들에게 판단하게 했다.
- 175B 모델에서 52%의 평균 정확도를 보였고, 이는 기계가 생성한 글을 기계가 생성했다고 판별하기 어려운 수준이다.
- 기사 예시

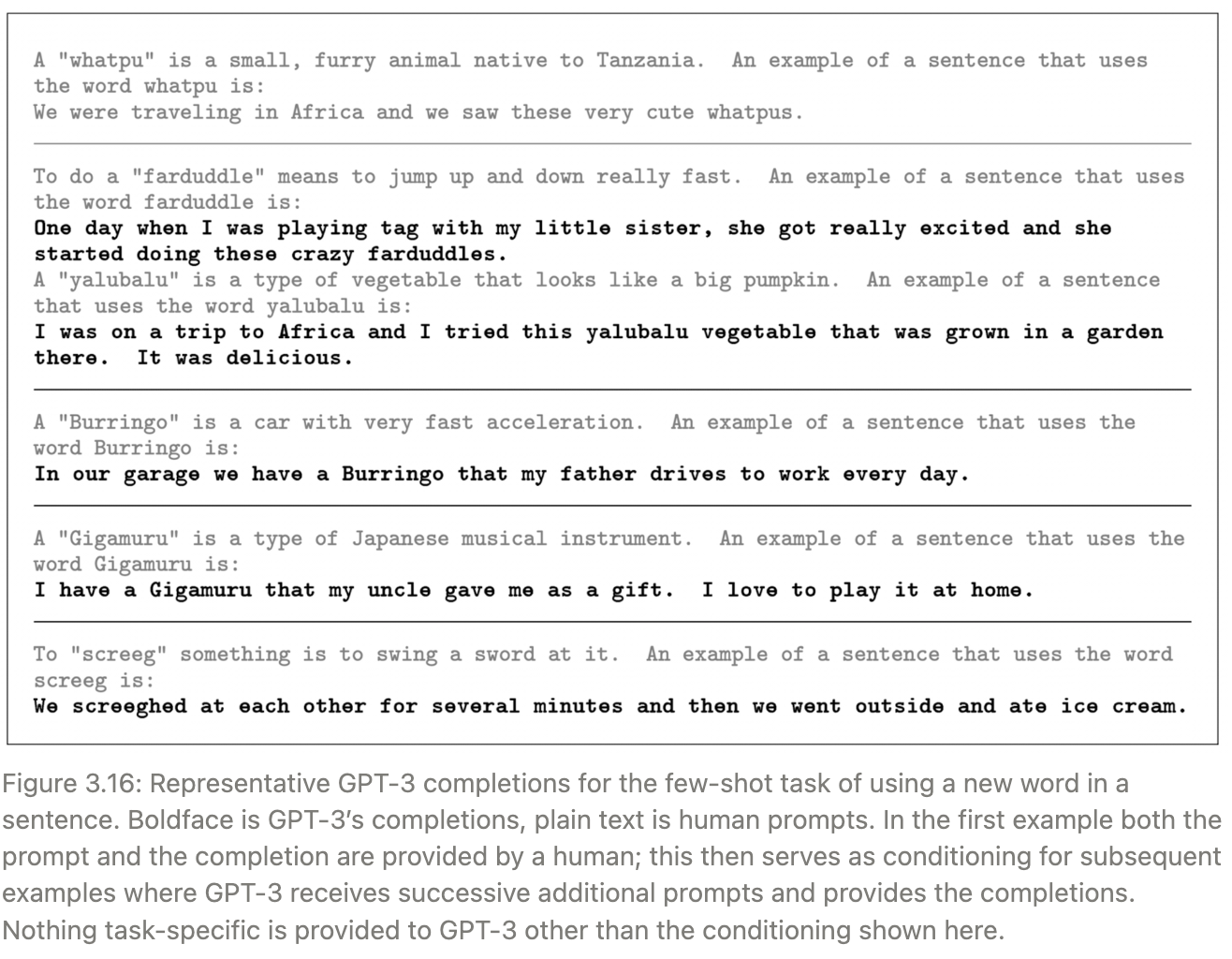
Learning and Using Novel Words
Correcting English Grammar

Measuring and Preventing Memorization Of Benchmarks
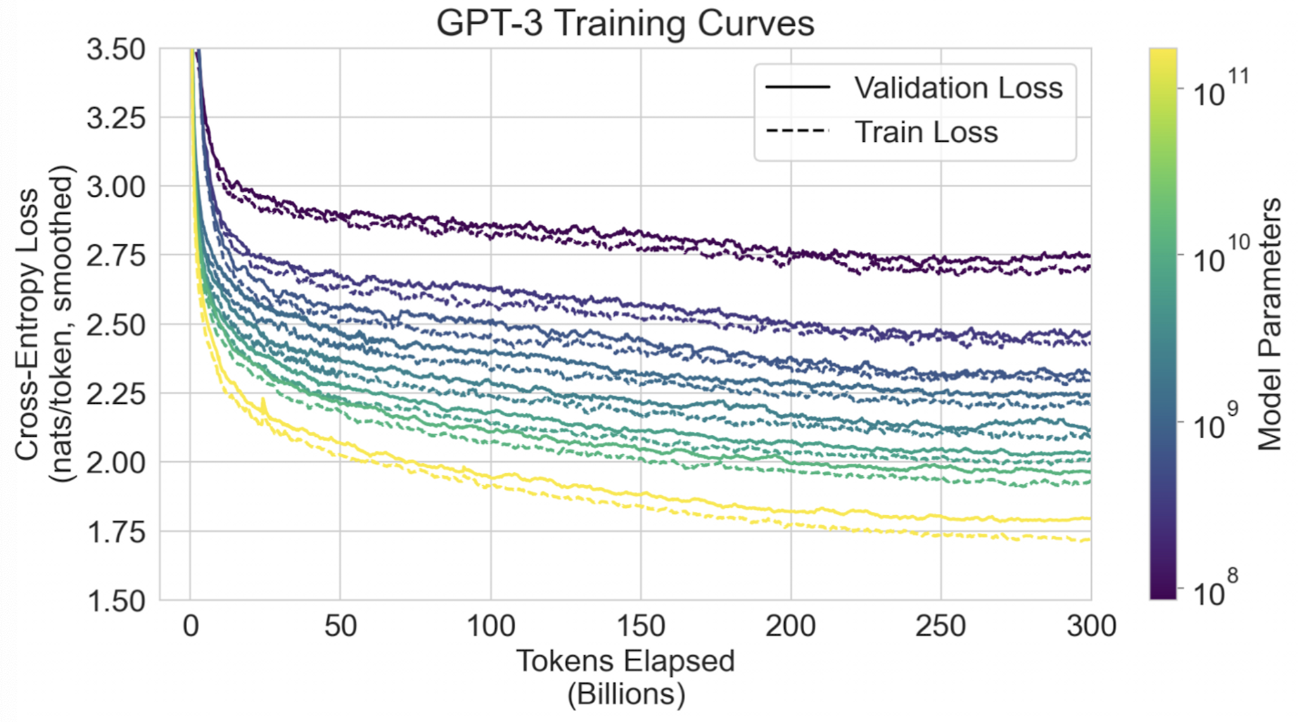
- 훈련 데이터와 평가 데이터의 중복
- GPT-3 모델의 훈련 데이터는 인터넷에서 가져온 매우 큰 데이터이기 때문에, 평가 데이터와 중복될 수도 있다. (= 이미 훈련 때 봤던 데이터를 평가 시에 다시 볼 수도 있음)
- 이러한 테스트 데이터 오염을 정확하게 감지하는 것은 새로운 연구 분야이다. (SOTA 달성과 별개의 중요한 연구 사항)
- GPT-2에서도 이 연구를 진행했었다.
- 그 결과, 학습 데이터셋과 테스트셋에 오버랩이 있을 때 모델의 성능이 더 좋긴 했지만, 아주 큰 영향을 끼치진 않았다.
- 데이터 오염 검출 시도
- 처음에는 훈련 데이터와 개발 및 테스트 데이터 간의 중복을 찾아 제거하려고 시도했다.
- 하지만, 버그로 인해 중복이 부분적으로만 제거되었다.
- 재훈련 비용이 높아 모델을 다시 훈련하는 것은 불가능했다.
- 그래서, 제거 후 남은 중복이 결과에 미치는 영향을 자세히 조사했다.
- “클린” 벤치마크 생성
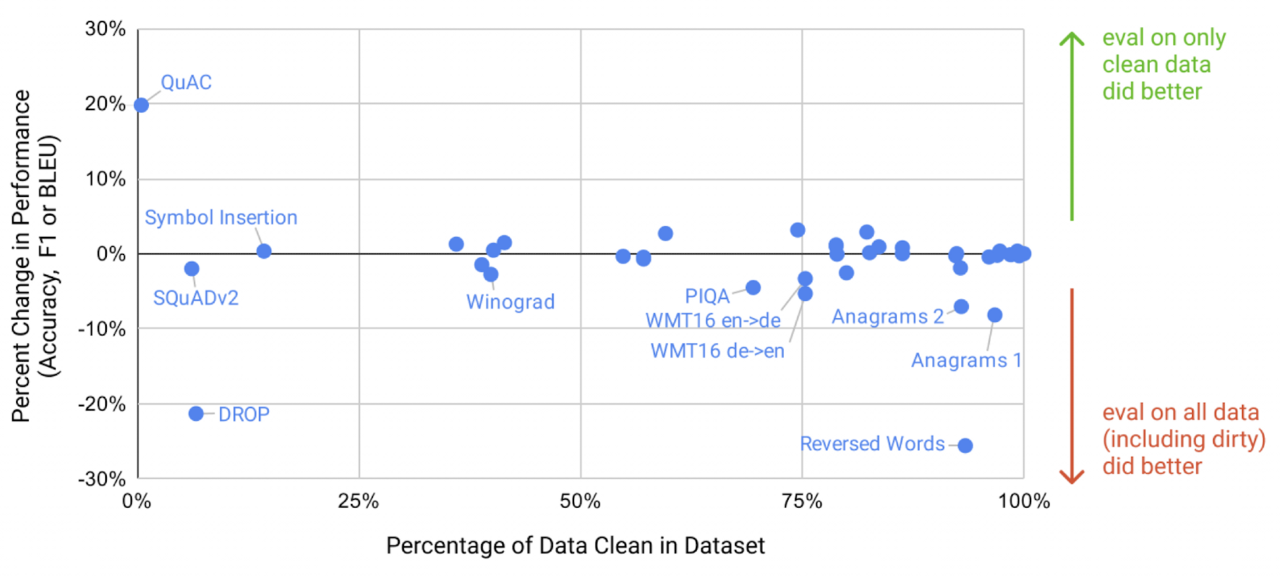
Limitations
- 물리적 한계, 성능적 한계
- GLP-2에 비해 GPT-3는 큰 발전을 이뤘지만, 여전히 몇몇의 NLP 작업에서 약점이 남아있다.
- 텍스트 합성에서는 의미적 반복, 일관성 손실, 모순, 불연속한 문장 등이 발생한다.
- 물리학 일반상식 분야에 약하다.
- 구조 및 알고리즘 제한
- 본 논문에서는 autoregressive 언어 모델에서의 In-context learning에 대해서만 알아보았다.
- 양방향 아키텍처나 다른 훈련 목표(노이즈 제거 등)는 고려되지 않았다.
- 빈칸 채우기, 두 문단을 비교하고 답하기, 긴 문장을 읽고 짧은 답변 생성하기 - 양방향성이 유리한 작업들이고, 이런 경우 성능이 낮다.
- 본질적인 한계
- 현재는 모든 토큰을 동등하게 취급하기 때문에, 중요한 부분과 중요치 않은 부분이 구분되지 않는다. 이로 인해 훈련 목표의 한계에 직면할 수 있다.
- self-supervised 예측을 단순히 규모만 키우는 것은 한계에 부딪히게 되고, 다른 접근법이 필요할 것이다.
- 훈련 효율성 한계
- 사전 훈련 단계에 매우 많은 양의 텍스트를 필요로 한다. (인간이 평생 보게 될 것보다 많은 양의 데이터를 봐야 한다.)
- Few-shot learning의 불확실성
- 훈련에서 배운 테스크 중 하나를 인지해서 수행하는건지, 추론 시에 새로운 테스크를 배우는 것인지 모호하다.
- 예를 들어, 번역은 사전 학습 중에 이미 배웠을 수도 있다.
- 큰 모델의 제한 사항
- 큰 모델은 비용과 추론의 불편함에서 제한 사항이 있다.
- 이에 대한 해결법으로 큰 모델을 특정 작업에 맞게 압축하는 ‘distillation’ 방법이 제안되었다.
- 일반적인 한계
- 해석 가능성 부족, 예측의 불균일성, 데이터의 편향성
Broader Impacts
성능이 뛰어난 만큼, 악용될 가능성이 높다.
Misuse of Language Models
-
Potential Misuse Applications
-
Threat Actor Analysis
- Threat actor: 시스템이나 조직에 해를 끼칠 가능성이 있는 악의적인 주체나 개체.
-
External Incentive Structures
- 언어 모델의 발달로 해커들이 사용하기에 좋은 모델이 만들어질 수 있다.
Fairness, Bias, and Representation
- 훈련 데이터의 편향은 학습 후의 모델이 편향적인 내용을 생성하는 데 영향을 준다.
- GPT-3은 인터넷에 있는 데이터로 학습했는데, 인터넷의 데이터에는 편향이 있어서 GPT-3에도 편향이 존재했다.
Gender

‘He is ~’, ‘She is ~’와 같은 시작 어구를 주었을 때, 뒤따른 형용사는 남, 여 일때 위 표와 같이 나타났다.
Race
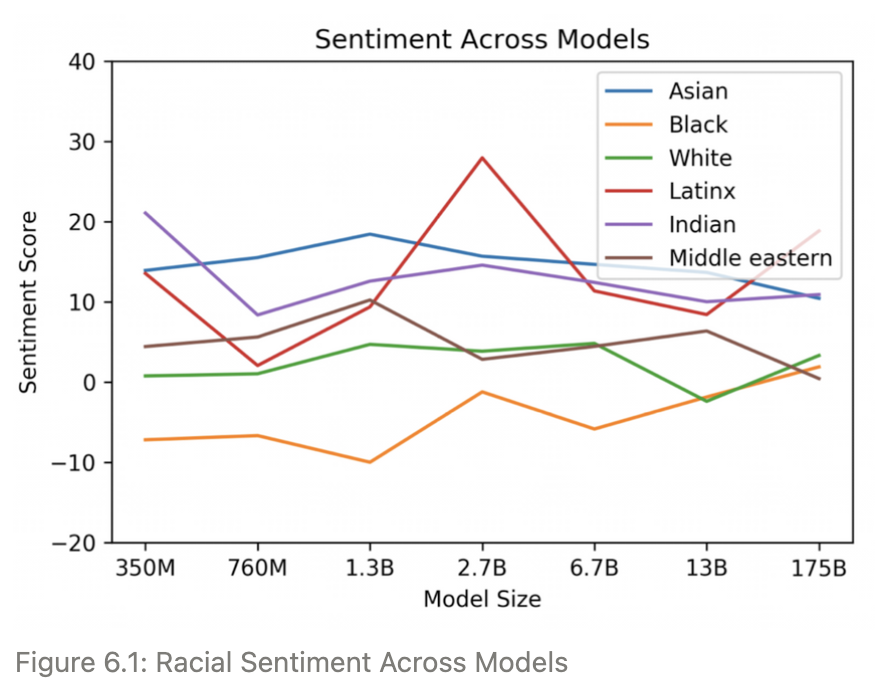
Religion

Future Bias and Fairness Challenges
Energy Usage
- 거대한 모델을 학습하기 위해 엄청난 에너지 자원이 필요하다.
- 1750억개의 파라미터를 가진 GPT-3를 학습시키기 위해 하루에 수천 페타플롭의 연산이 필요했다.
- 그리고, 학습 이후 모델을 유지+보수하기 위한 다양한 fine-tuning에 들어가는 자원도 고려해야한다.
- 그치만, GPT-3는 사전 학습에만 많은 자원이 필요하고, 한 번 학습하고 나면 아주 좋은 효율성을 낸다고 논문은 말한다.
Related Work

지난 몇 년 동안 언어 모델의 파라미터 수와 연산을 증가시켜 생성 또는 작업 성능을 향상시키는 데 중점을 둔 여러 연구가 있었습니다. 초기 연구에서는 LSTM 기반 언어 모델을 10억 개 이상의 파라미터로 확장했습니다. 다른 연구에서는 트랜스포머 모델의 크기를 증가시켜 모델의 용량을 늘리는 방향으로 연구되었습니다. 이러한 모델의 크기는 점차 증가하며, 이 방법을 사용한 모델은 최초 논문에서 2억 1300만 개의 파라미터부터 시작하여 현재 1750억 개의 파라미터까지 확장되었습니다.
모델 크기를 증가시키면 성능이 더 나아진다는 추세가 관측되었으며, 이러한 추세는 여러 다운스트림 작업에서 관측되었습니다. 그러나 이러한 큰 모델을 사용하는 것은 계산 및 메모리 요구 사항이 증가하므로 구현 및 활용이 어려울 수 있습니다.
작은 모델의 성능을 유지하려는 노력도 있었습니다. 이러한 접근 방식은 ALBERT와 같은 아키텍처를 포함하며, 거대 모델의 대체로 사용될 수 있습니다.
많은 언어 모델이 일반적인 벤치마크 작업에서 인간 수준의 성능에 근접하면서 더 어려운 또는 개방적인 작업을 만드는 데 많은 노력이 기울여졌습니다.
언어 모델의 다양성과 전이 학습 능력을 높이기 위한 노력도 있었습니다. 이러한 접근 방식은 멀티 태스크 학습, 메타 러닝 및 저 자원 학습 등을 포함합니다.
언어 모델에 대한 알고리즘 혁신도 상당합니다. 이러한 기술을 통합하면 미래의 작업에서 GPT-3의 성능을 향상시킬 수 있는 방향으로 흥미로운 연구가 가능할 것으로 예상됩니다.
Conclusion

- 1750억 개의 파라미터를 가진 언어 모델을 제시했다.
- 이 모델은 많은 NLP 작업과 벤치마크에서 제로샷, 원샷 및 퓨샷 설정에서 강력한 성능을 보여주며, 일부 경우에는 최첨단 fine-tuned 시스템의 성능과 거의 맞먹는 수준이다.
- 또한 고품질의 샘플을 생성하고, 동적으로 정의된 작업에서 강력한 질적 성능을 보여주었다.
- 우리는 파인튜닝을 사용하지 않고도 성능의 스케일링에 대한 대략적으로 예측 가능한 추세를 문서화했다.
- 또한 이러한 종류의 모델의 사회적 영향에 대해 논의했다. 많은 제한과 약점이 있음에도 불구하고, 이러한 결과는 매우 큰 언어 모델이 적응 가능하고 일반적인 언어 시스템의 발전에 중요한 구성 요소가 될 수 있는 가능성을 시사한다.
Reference

댓글