RAG 논문 리뷰 - "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"

∣
2024년 11월 10일

사전 학습된 대규모 언어 모델은 파인튜닝을 통해 좋은 성능을 낼 수 있지만 모델들은 답을 제시할 수는 있지만, 그 답이 왜 맞는지에 대한 구체적인 근거를 충분히 제시하는 데에는 어려움있고 새로운 지식을 반영하는데 어려움이 있다.
때문에 사전 학습된 매개변수 기반 메모리(파라메트릭 메모리)와 비모수 메모리(비파라메트릭 메모리)를 결합한 모델인 검색 증강 생성(RAG) 모델을 제안하며, 사전 학습된 seq2seq 모델을 파라메트릭 메모리로, 조밀 벡터 인덱스로 저장된 위키피디아의 정보를 비파라메트릭 메모리로 활용하여 구현했다고 한다.
연구는 두 가지 방법을 시도했다.
전체 시퀀스에 동일한 구절을 사용하는 방식 하나의 구절을 선택하고, 그 구절을 사용해 처음부터 끝까지 텍스트를 생성
각 토큰마다 다른 구절을 사용할 수 있는 방식 텍스트를 생성하는 동안 필요한 토큰마다 다른 구절을 선택해서 사용합니다. 이를 통해 생성 중에도 필요한 정보가 다른 구절에서 동적으로 가져와지는 방식
현 LLM은 상당한 양의 데이터를 학습하는 것으로 매개변수화된 암묵적 지식 기반으로서 외부 메모리에 대한 액세스 없이도 답변이 생성 가능하다.
하지만 메모리를 쉽게 확장하거나 수정할 수 없고, 예측에 대한 인사이트를 직접 제공할 수 없으며, “환각”을 생성할 수 있다
매개 변수 메모리와 비 매개 변수(즉, 검색 기반) 메모리를 결합하는 하이브리드 모델은 지식을 직접 수정 및 확장하고 액세스한 지식을 검사 및 해석할 수 있기 때문에 이러한 문제 중 일부를 해결할 수 있다
때문에 파라메트릭 메모리가 사전 학습된 seq2seq 변환기이고 비파라메트릭 메모리가 사전 학습된 뉴럴 리트리버로 액세스되는 위키피디아의 조밀한 벡터 인덱스인 RAG 모델을 구축한다.
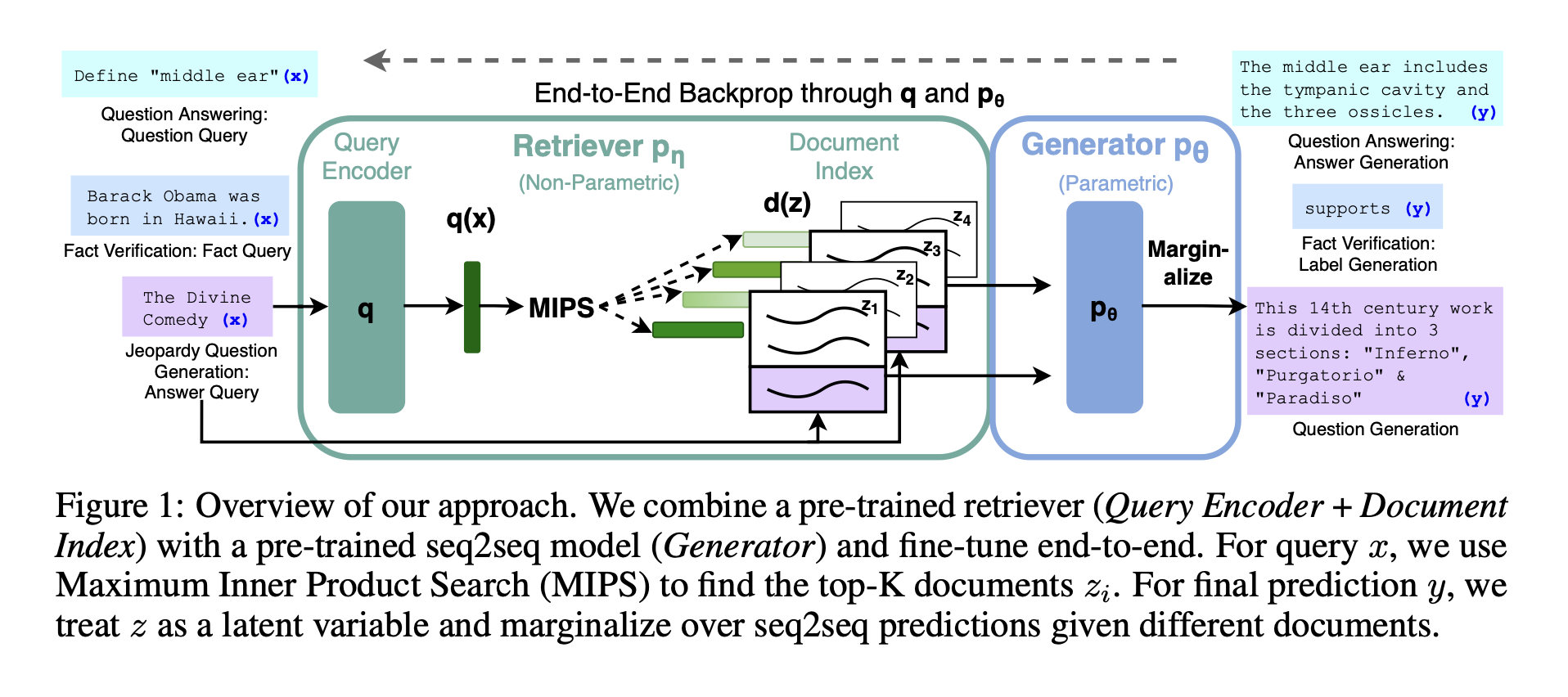
RAG 모델은 생성기와 리트리버가 공동으로 학습되며, 추가 학습 없이도 사전 학습된 메커니즘을 통해 지식에 접근할 수 있습니다. 이 연구는 파라메트릭과 비파라메트릭 메모리 조합이 지식에 대한 접근성을 높여 지식 집약적인 작업에서 효과적으로 성능을 향상시킬 수 있음을 강조한다.
리트리버 (Query Encoder + Document Index) Query Encoder는 입력 질문(x)을 벡터로 변환한다. Document Index는 문서들을 사전에 인덱싱해 두고, 각 문서를 벡터로 표현하여 저장해둔다. Maximum Inner Product Search (MIPS): 질문 벡터와 인덱스화된 문서 벡터 간의 내적을 계산해 가장 유사한 K개의 문서(z_i)를 찾는다.
생성기 (Generator): seq2seq 모델인 생성기는 선택된 문서들(z_i)을 조건으로 질문(x)에 대한 답변(y)을 생성한다.
잠재 변수 마진화 (Marginalization over z): 각 문서를 잠재 변수(z)로 간주하여, 다양한 문서에 기반해 생성된 답변들(seq2seq predictions)을 종합해 최종 예측(y)을 도출한다.
RAG-Sequence 모델은 하나의 검색된 문서를 사용하여 전체 출력 시퀀스를 생성한다. 검색된 문서를 하나의 잠재 변수로 간주하여 이를 마진화하여 전체 시퀀스에 대한 확률 ( p(y|x) )을 계산한다. 이를 위해 top-K 문서를 검색하고, 각 문서에 대해 출력 시퀀스의 확률을 생성한 후 마진화한다.
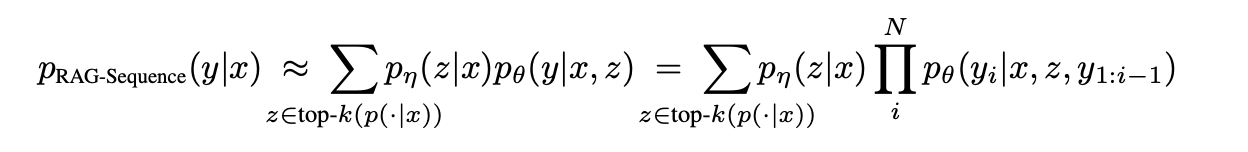
이 방식에서 생성기는 전체 출력 시퀀스를 하나의 문서에 기반하여 생성하므로, 선택된 문서가 시퀀스의 모든 토큰에 대한 정보를 제공한다.
RAG-Token 모델은 각 목표 토큰마다 다른 문서를 사용할 수 있도록 허용한다. 즉, 생성기는 여러 문서에서 정보를 가져와 각 토큰을 예측할 수 있다. 이 모델은 목표 시퀀스의 각 토큰 ( y_i )에 대해 다른 문서를 잠재 변수로 사용하며, 이를 마진화하여 최종 출력 확률을 계산한다.
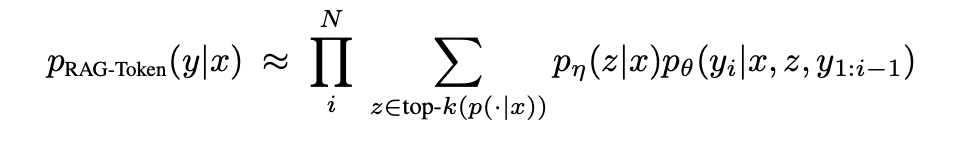
이 방식은 여러 문서의 내용을 조합하여 답변을 생성할 수 있어 다양한 정보가 필요한 질문에 유리합니다.
RAG 모델의 두 가지 주요 구성 요소인 리트리버(DPR)와 생성기(BART)에 대해 자세히 설명하겠습니다.
리트리버 pη(z∣x)는 DPR을 기반으로 하며, bi-encoder 아키텍처를 따릅니다. 이 모델은 입력 쿼리 x에 대해 가장 관련성 높은 문서들을 검색하는 역할을 한다.
문서 인코더와 쿼리 인코더 두 가지 BERT 모델을 사용하여 쿼리와 문서를 독립적으로 임베딩한다.
d(z) = BERT_d(z): 문서 인코더를 통해 문서 z의 임베딩 ( d(z) )을 생성q(x) = BERT_q(x): 쿼리 인코더를 통해 입력 쿼리 x의 임베딩 ( q(x) )을 생성유사도 계산: 두 임베딩의 내적 d(z)⊤q(x)을 통해 유사도를 계산합니다. 이 유사도가 높을수록 쿼리와 문서가 관련성이 높다는 뜻이다.
최대 내적 검색 (MIPS): 가장 높은 유사도를 갖는 top-K 문서들을 선택하는 것은 Maximum Inner Product Search (MIPS) 문제로, sub-linear 시간에 근사적으로 해결할 수 있다.
생성기 pθ(yi|x, z, y1:i−1)는 BART-large 모델을 기반으로 합니다. 이는 임베딩된 입력 x와 검색된 문서 z를 결합하여 최종 답변을 생성합니다.
BART 구조: BART는 400M 개의 파라미터를 가진 사전 학습된 seq2seq 트랜스포머로, 디노이징 목표(denoising objective)로 사전 학습되었습니다. 이는 입력에 다양한 형태의 노이즈를 추가한 후 이를 복원하는 방식으로 학습되어, 다양한 생성 작업에 강력한 성능을 보입니다.
입력 결합: BART를 사용할 때, 입력 x와 검색된 콘텐츠 z를 단순히 이어붙여(concatenate) 입력으로 사용합니다. 이를 통해 BART는 질문과 문서의 정보를 통합하여 답변을 생성할 수 있습니다.
파라메트릭 메모리: BART 생성기의 파라미터 θ는 파라메트릭 메모리로 기능합니다. 즉, BART가 사전 학습을 통해 내장한 지식과 더불어 리트리버가 가져온 외부 문서 정보를 활용하여 더 정확한 답변을 생성합니다.
RAG 모델은 리트리버와 생성기를 함께 학습하지만, 어떤 문서가 검색되어야 하는지에 대한 직접적인 감독(supervision)은 없다. 일반적인 인공지능 학습방법으로 학습을 한다.
문서 인코더 고정: 문서 인코더 ( \text{BERT}_{d} )를 학습하는 것은 매우 비용이 많이 드는 작업이다. 학습 중 문서 인덱스를 자주 업데이트해야 하는 REALM의 방식과 달리, 우리는 문서 인코더와 문서 인덱스를 고정한다. 대신, 쿼리 인코더 ( \text{BERT}_{q} )와 BART 생성기만 미세 조정한다.
테스트 시점에서 RAG-Sequence와 RAG-Token 모델은 서로 다른 방식으로 arg max_y p(y|x)를 근사화하여 답변을 생성합니다.
실험에 사용된 비매개 변수 지식 소스는 2018년 12월 위키백과 덤프이며, 각 문서를 100단어로 분리해 2천1백만 개의 문서를 포함하는 MIPS 인덱스를 구축하고, FAISS를 활용하여 효율적으로 검색한다.
오픈 도메인 질문 답변(Open-domain Question Answering): 여러 오픈 도메인 QA 데이터셋을 활용해 질문과 답변 쌍을 학습하고, 기존의 추출 기반 QA 및 폐쇄형 QA와 비교했다. 성능 평가는 Exact Match(EM) 점수를 사용
추상적 질문 답변(Abstractive Question Answering): MSMARCO NLG v2.1 데이터셋을 사용해 RAG의 자연어 생성 능력을 테스트했다. 주어진 질문과 답변만으로 학습하며, 위키백과 데이터만으로는 답변할 수 없는 일부 질문들도 포함
제퍼디 질문 생성(Jeopardy Question Generation): SearchQA 데이터셋을 활용해 RAG 모델이 특정 엔티티에 대한 사실을 기반으로 제퍼디 스타일의 질문을 생성하는 능력을 평가했다. SQuAD-tuned Q-BLEU-1 메트릭을 사용하여 모델의 성능을 측정하고, 인간 평가를 통해 생성된 질문의 사실성과 구체성을 평가했다.
사실 검증(Fact Verification): FEVER 데이터셋을 사용해 RAG 모델이 주어진 주장을 위키백과에서 추출한 증거를 바탕으로 사실을 검증할 수 있는지를 평가했다. 세 가지 레이블(지원, 반박, 정보 부족)을 기준으로 분류하고, 레이블 정확도를 보고합니다. RAG는 검색된 증거에 대한 감독 없이 훈련하여, 감독 없이도 적용 가능한 모델의 가능성을 탐구했다.
오픈 도메인 질문 답변(Open-domain QA): RAG는 TQA 데이터셋의 T5와 비교 가능한 분할에서 새로운 최고 성능을 기록했으며, 추출 기반 모델의 리랭커나 추출 리더 없이도 높은 성능을 달성했다. 추출형 모델이 정답을 명시적으로 포함하지 않는 문서에서 정보를 얻기 어려운 반면, RAG는 정답을 생성할 수 있는 이점이 있다.
추상적 질문 답변(Abstractive QA): MS-MARCO NLG에서 RAG-Sequence는 BART보다 높은 BLEU 점수와 ROUGE-L 점수를 기록했다. RAG 모델은 BART보다 사실적이고 정확한 응답을 생성하며, 이를 통해 지식 집약적인 작업에서의 추론 능력을 보여주었다.
제퍼디 질문 생성(Jeopardy Question Generation): RAG-Token 모델은 제퍼디 질문 생성에서 BART보다 구체적이고 사실적인 질문을 생성했으며, 인간 평가에서도 BART보다 높은 점수를 받았다. 이는 RAG가 여러 문서에서 정보를 통합해 질문을 생성하는 능력을 보여준다.
사실 검증(Fact Verification): FEVER 데이터셋에서 RAG는 복잡한 파이프라인 시스템과 비슷한 성능을 기록했다. RAG는 검색 감독 신호 없이도 학습할 수 있어, 실제 응용에서 유용할 수 있다.
추가 실험 결과: 문서 검색 및 업데이트, 인덱스 변경의 효과, 그리고 문서 검색 개수를 늘리는 것의 성능 변화를 실험하여 RAG의 유연성과 효율성을 확인했다.
단일 작업 검색 기존 연구에서는 검색이 개별 NLP 작업의 성능을 향상시키는 것으로 확인됐다. 이러한 작업에는 오픈 도메인 질문 응답, 사실 검증, 사실 보완, 장문 질문 응답, 위키백과 문서 생성, 대화, 번역, 언어 모델링 등이 포함된다. 본 연구는 이러한 검색 기반 성공 사례들을 하나의 아키텍처로 통합하여 다양한 작업에서 높은 성능을 달성할 수 있음을 보여준다.
NLP를 위한 범용 아키텍처 기존에는 검색 없이도 단일 사전 학습된 언어 모델로 여러 NLP 작업에서 좋은 성능을 달성하는 연구들이 있었다. 예를 들어 GPT-2는 단방향 사전 학습 모델로 분류와 생성 작업에서 모두 강력한 성능을 보였고, BART와 T5는 양방향 주의(attention) 메커니즘을 활용해 분류 및 생성 작업의 성능을 더 향상했다. 본 연구는 이러한 범용 아키텍처에 검색 모듈을 추가하여 사전 학습된 생성 언어 모델의 작업 확장 가능성을 탐구했다.
학습된 검색 학습을 통해 정보 검색 성능을 향상시키려는 시도가 많다. 예를 들어, 질문 응답 같은 특정 작업을 위해 검색 모듈을 최적화하는 연구들이 있으며, 본 연구에서는 여러 작업에서 강력한 성능을 발휘하는 검색 기반 아키텍처를 제안한다.
메모리 기반 아키텍처 본 연구의 문서 인덱스는 신경망이 외부 메모리를 참조하는 역할을 한다. 이는 TF-IDF 대신 학습을 통해 검색된 텍스트를 기반으로 지식을 생성하는 방식으로, 인간이 읽고 쓸 수 있어 해석 가능성과 동적 업데이트가 용이하다.
검색 및 편집 방식 본 연구는 검색 및 편집 방식과 유사한 면이 있다. 그러나 기존 방식과 달리 검색된 콘텐츠를 부분적으로 수정하기보다, 여러 콘텐츠를 집계하여 증거 문서를 검색하고 이를 기반으로 최종 결과를 생성하는 방식을 채택한다. RAG 기술을 이러한 환경에 적용할 수 있는 가능성도 존재하며, 이는 향후 연구 방향이 될 수 있다.
본 연구에서는 매개변수적 메모리와 비매개변수적 메모리에 접근할 수 있는 하이브리드 생성 모델을 제시한다. 제안한 RAG 모델은 오픈 도메인 질문 응답에서 최첨단 성능을 달성했으며, 사용자는 순수 매개변수적 BART보다 RAG 모델의 생성 결과를 더욱 사실적이고 구체적으로 평가했다. 학습된 검색 구성 요소에 대한 철저한 조사를 통해 그 효과성을 검증했고, 검색 인덱스를 실시간으로 교체하여 모델을 재학습하지 않고도 업데이트할 수 있음을 입증했다. 앞으로는 두 구성 요소를 BART의 디노이징(dnoising) 목적과 유사한 방식 또는 다른 목표로 처음부터 공동 사전 학습하는 연구가 유망할 것이다. 본 연구는 매개변수적과 비매개변수적 메모리가 어떻게 상호 작용하는지, 이를 최적으로 결합하는 방법에 대한 새로운 연구 방향을 열었으며, 다양한 NLP 작업에 적용 가능성이 있음을 보여준다.
댓글